
Un test pratique du nouveau modèle lancé discrètement par DeepSeek : la programmation est meilleure que Claude 4, mais l’écriture… eh bien, oubliez ça Œuf de Pâques inclus

Depuis la sortie de GPT-5, le fondateur de DeepSeek, Liang Wenfeng, est devenu la personne la plus occupée du monde de l'IA.
Les internautes et les médias réclament régulièrement des mises à jour, soit pour « mettre la pression sur Liang Wenfeng », soit pour « attendre la réponse de Liang Wenfeng ». Bien que DeepSeek R2 ne soit pas encore disponible, DeepSeek a officiellement lancé et rendu open source son nouveau modèle, DeepSeek-V3.1-Base, aujourd'hui.
Comparé à Ultraman qui dressait encore un grand tableau de GPT-6 lors d'une interview ce matin, l'arrivée du nouveau modèle de DeepSeek semble assez bouddhiste, et même le numéro de version semble être une "réparation mineure", mais dans l'expérience réelle, cette mise à jour m'a quand même réservé beaucoup de surprises.
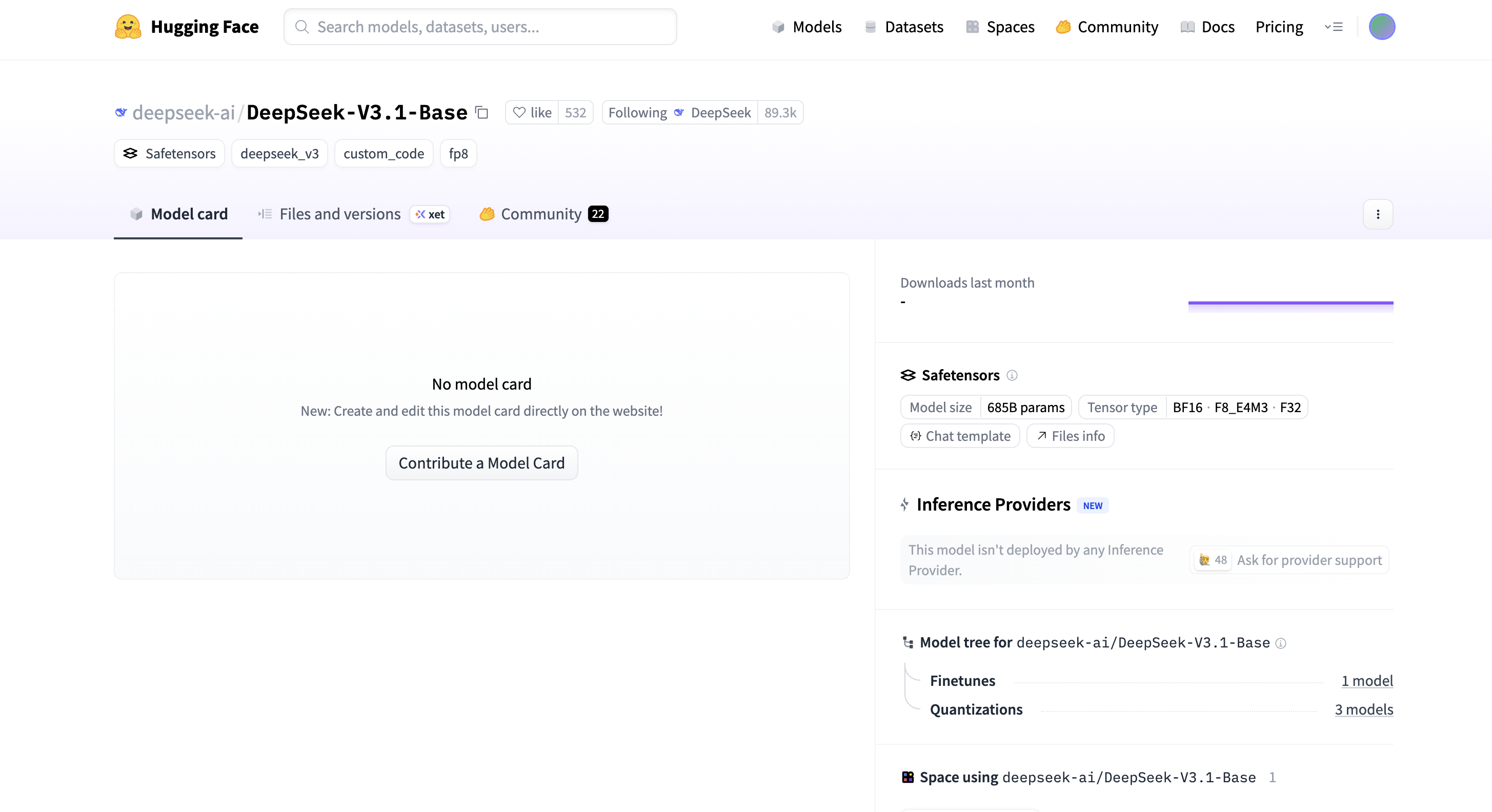
DeepSeek-V3.1-Base compte 685 milliards de paramètres, prend en charge trois types de tenseurs : BF16, F8_E4M3 et F32, est publié au format Safetensors et a apporté de nombreuses optimisations pour l'efficacité de l'inférence. La fenêtre contextuelle de la version en ligne du modèle a également été étendue à 128 k.
Nous avons donc commencé à tester sur le site officiel sans rien dire.
Ci-joint l'adresse de l'expérience :
https://chat.deepseek.com/
Pour tester la capacité de la V3.1 à gérer de longs textes, j'ai trouvé le texte complet de « The Three-Body Problem », je l'ai réduit à environ 100 000 mots, puis j'ai secrètement inséré une phrase complètement sans rapport dans le texte : « Je pense que la deuxième ligne de « Smoke locks the pond willows » devrait être « Shenzhen Teppanyaki » » pour voir s'il peut le récupérer avec précision.

Sans surprise, DeepSeek V3.1 s'est d'abord plaint de la surcharge du document et n'a lu que les 92 % du contenu initial, mais a tout de même réussi à trouver la phrase. Plus intéressant encore, il a judicieusement suggéré une deuxième ligne classique d'un point de vue littéraire : « Les flammes brûlent l'érable du barrage marin. »
Les internautes l'ont déjà testé sur le benchmark de programmation Aider Polyglot et ont obtenu un score de 71,6 %, ce qui non seulement est le meilleur parmi les modèles open source, mais a même battu Claude 4 Opus.
Après des tests réels, nous avons constaté que la version 3.1 est en effet très bonne en programmation.
Nous l'avons testé avec le problème classique de programmation de balle hexagonale : « Écrivez un programme p5.js qui illustre une balle rebondissant à l'intérieur d'un hexagone en rotation. La balle doit être affectée par la gravité et la friction et doit rebondir de manière réaliste sur les parois en rotation. »

La version 3.1 est assez impressionnante : elle génère du code qui gère non seulement la détection de collision de base, mais aussi des informations comme la vitesse de rotation et la gravité. La physique est si réaliste que la balle ralentit légèrement en bas.
Ensuite, nous avons augmenté la complexité et utilisé Three.js pour créer une galaxie de particules 3D interactive. Le framework de base était solide et la conception à trois couches (sphère intérieure, anneau central, sphère extérieure) était relativement aboutie, mais l'esthétique de l'interface utilisateur était… disons, un peu éthérée, avec une palette de couleurs légèrement criarde.
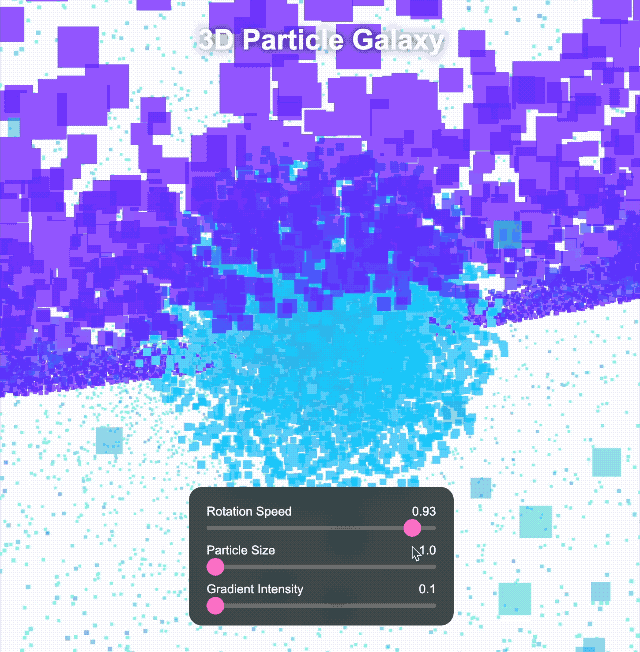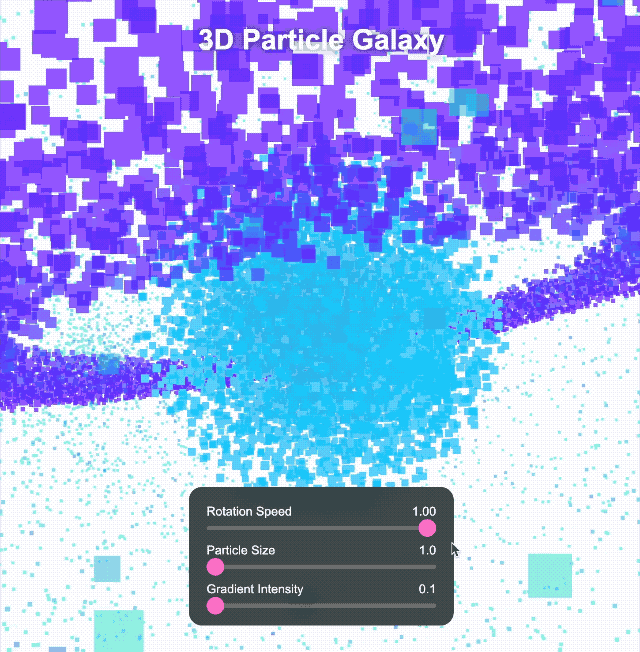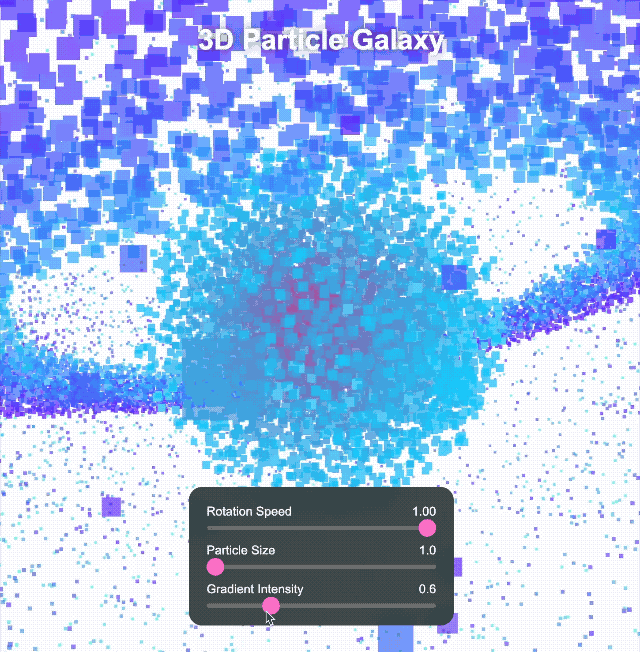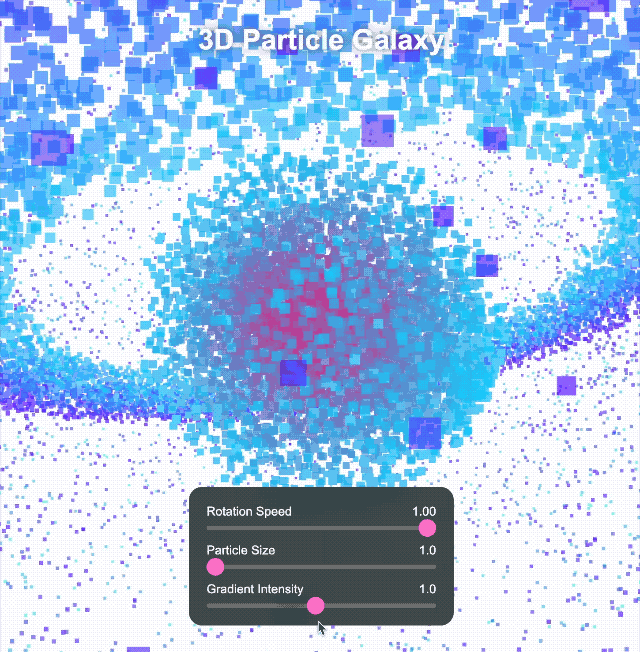
Nous avons continué à relever des défis plus complexes. Nous lui avons demandé de créer un univers 3D immersif avec des objets rotatifs, des effets de déformation, des arcs lumineux et des boutons interactifs pour le changement de temps et de thème. Les commandes cliquables peuvent également déclencher différents effets spéciaux.

L'étape finale consistait à créer une visualisation interactive du réseau en 3D à l'aide de Three.js, incluant une animation d'impulsions énergétiques déclenchée par l'utilisateur, le changement de thème et le contrôle de la densité. Les performances étaient globalement acceptables.

Il y a un pâturage avec 27 vaches. Il leur faut 6 jours pour brouter toute l'herbe. Si vous élevez 23 vaches, il leur faut 9 jours pour brouter toute l'herbe. Si vous élevez 21 vaches, combien de jours leur faudra-t-il pour brouter toute l'herbe ? Et l'herbe du pâturage pousse constamment.
Bien que DeepSeek V3.1 n'utilise pas d'approche socratique, ses solutions sont logiquement claires et détaillées. Chaque étape est bien argumentée et fournit une réponse précise. Cette base mathématique solide est vraiment impressionnante.

Lorsqu'on se demande « Quelle arme est la plus puissante, 1 à 5 coups contre 2 à 4 coups ? », la réponse habituelle consisterait à calculer simplement les dégâts moyens. Cependant, DeepSeek V3.1 va encore plus loin en introduisant le concept de stabilité des dégâts et en utilisant la variance pour une analyse approfondie.

Lorsqu'on lui a posé une question géographique spécifique comme « Y a-t-il des moustiques en Islande ? » sans activer la recherche, la réponse de DeepSeek V3.1 a nettement surpassé celle de GPT-5. Cela démontre non seulement sa vaste base de connaissances, mais aussi sa capacité précise à extraire et à intégrer des informations.
Avec la récente épidémie de chikungunya et les efforts massifs de lutte contre les moustiques, je suis curieux : y a-t-il des moustiques en Islande ? Remarque : je n'ai pas activé la fonction de recherche. À en juger par la qualité des réponses, DeepSeek V3.1 a clairement surpassé GPT-5.
J'ai vu un passage en ligne il y a quelque temps :
Ceux qui comprennent doivent comprendre leur compréhension, tandis que les ignorants resteront ignorants. La compréhension est le secret tacite du Ciel, mais comment sa révélation peut-elle être compréhension ? La compréhension est la compréhension du vide et du non-vide, et du non-non-vide ; l’ignorance est la compréhension de la couleur et du vide, et du vide et de la couleur. La compréhension vient des trois mille grands mondes, tandis que l’ignorance erre entre cette rive et l’autre. Comprendre, c’est voir les montagnes non comme des montagnes lorsqu’on comprend, et voir les montagnes comme des montagnes lorsqu’on ne comprend pas. Ceux qui comprennent utilisent leur ignorance pour prouver leur compréhension, tandis que les ignorants utilisent leur compréhension pour prouver leur ignorance. Vous dites comprendre la différence entre comprendre et ne pas comprendre ? Comment savez-vous que derrière cette compréhension, il n’y a pas une compréhension plus grande ? Ceux qui prétendent comprendre ne comprennent pas vraiment. La compréhension silencieuse est la grande compréhension tacite du ciel et de la terre. Une compréhension qui n’est pas compréhension est compréhension, et une compréhension qui n’est pas compréhension est aussi compréhension. C’est le royaume suprême de la compréhension : la compréhension de la véritable vacuité et de l’existence merveilleuse qui ne peut être comprise !

Alors que j'utilisais encore la logique pour digérer ce texte, DeepSeek me conseillait de ne pas tomber dans le piège du « comment puis-je comprendre le secret si je le révèle » – c'est en soi un avertissement contre l'arrogance rationnelle, vous invitant à sortir du jeu de mots et à regarder directement dans votre cœur.
Alors que l'IA grand public s'efforce de développer des agents, en se concentrant sur le codage et les mathématiques, les compétences rédactionnelles sont devenues un domaine oublié. D'une certaine manière, c'est une bonne nouvelle : le jour où l'IA remplacera complètement les éditeurs semble avoir été repoussé.
J'ai essayé de créer une histoire ridicule à propos d'un moustique tenant une conférence de presse en Islande. Malheureusement, DeepSeek V3.1 conserve une forte influence de l'IA et un penchant pour les grands mots. Ou plutôt, il conserve cette forte influence de DeepSeek.
Le même problème est également apparu dans une autre tâche créative.
Lorsque je lui ai demandé d'écrire un article sur « l'IA et les humains en compétition pour la rédaction d'un article », j'ai clairement senti que la densité d'information de certains paragraphes était trop élevée, ce qui provoquait une fatigue visuelle. En particulier, l'imagerie était trop évidente, ce qui affaiblissait la tension narrative.

Après la sortie de DeepSeek-V3.1-Base, Clément Delangue, PDG de Hugging Face, a publié sur la plateforme X : « DeepSeek V3.1 est classé quatrième sur HF. Il a été publié discrètement et ne nécessite pas de carte modèle. » Cependant, il a sous-estimé l'importance de ce modèle.
Il est désormais passé à la deuxième place et ce n’est probablement qu’une question de temps avant qu’il n’atteigne le sommet.
Le changement le plus notable de cette mise à jour est la suppression du logo « R1 » de l'application et du site web officiels de DeepSeek. De plus, DeepSeek R1 prend en charge nativement les jetons de recherche, optimisant ainsi davantage la fonctionnalité de recherche.
Parallèlement, certains spéculent sur le fait que DeepSeek V3.1 pourrait être un modèle hybride intégrant des modèles d'inférence et de non-inférence. Cependant, la pertinence d'une telle approche technique reste à déterminer. L'équipe Alibaba Qwen a également déclaré le mois dernier :
Après consultation et réflexion approfondie avec la communauté, nous avons décidé d'abandonner le modèle hybride de réflexion. Nous formerons désormais les modèles Instruct et Thinking séparément afin d'obtenir une qualité optimale.
Au moment de la publication, la carte DeepSeek-V3.1-Base, attendue avec impatience par l'ensemble du réseau, n'avait pas encore été mise à jour. Peut-être qu'après sa sortie officielle, nous aurons accès à des détails techniques plus intéressants.
Adresse du visage qui fait un câlin :
https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
#Bienvenue pour suivre le compte public officiel WeChat d'iFaner : iFaner (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.