
DeepSeek V3.1 a soudainement rencontré un bug scandaleux : le mot « 极 » est apparu partout sur l’écran, laissant les développeurs confus
La dernière version de DeepSeek, V3.1, a été testée par plusieurs développeurs et il a été constaté qu'elle insérait des jetons tels que « 极/極/extreme » là où ils ne devraient pas apparaître.
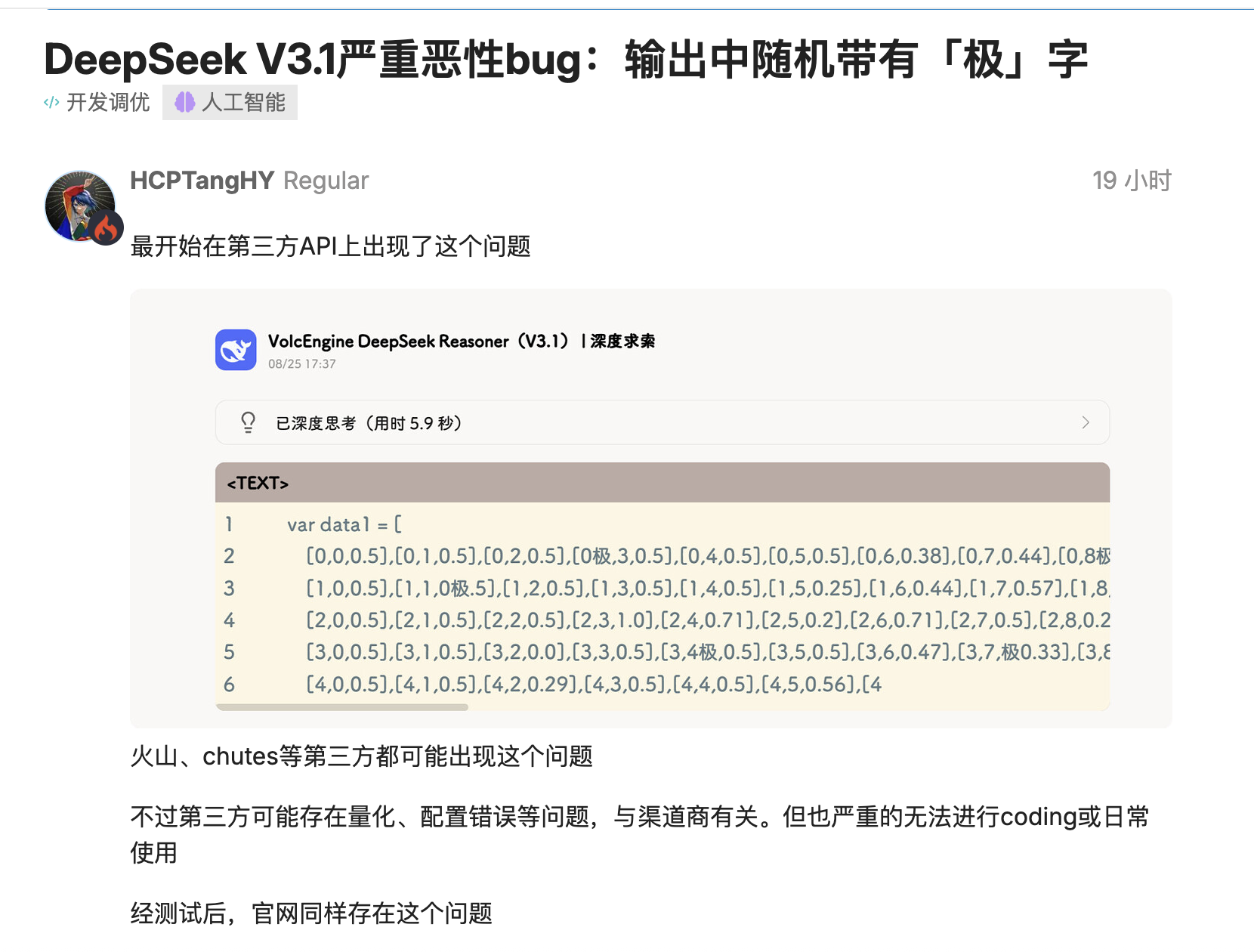
`time.Second` devient `time.Second` et le numéro de version `V1` devient `V`. Pire encore, ce problème se produit non seulement dans les déploiements quantitatifs tiers, mais aussi dans les déploiements officiels de haute précision, affectant le processus d'encodage.
Les utilisateurs de la communauté open source ont fourni plusieurs scénarios reproductibles : dans la génération de langage comme Go, le modèle « collerait » des jetons aux identifiants, insérant aléatoirement « 极/極/extreme » avant « Second », et même un décodage conservateur avec « top_k=1, temperature=1 » ne parviendrait pas à éviter cela.
Certains ont d'abord soupçonné que cela était dû à une quantification très faible ou à des effets de bord dans le jeu de données d'étalonnage, mais le même problème a ensuite été reproduit sur d'autres sites web utilisant des versions FP8 de précision maximale, indiquant qu'il ne s'agissait pas simplement d'un problème de déploiement. Conclusion : Le code précédemment compilé avec succès a soudainement cessé de compiler.
Ce n'est pas la première fois que DeepSeek est confronté à des bugs depuis sa mise à jour. La dernière fois, c'était lors de tâches d'écriture, où une confusion de langage s'était produite. Et pour les tâches de codage, on soupçonne un surapprentissage.
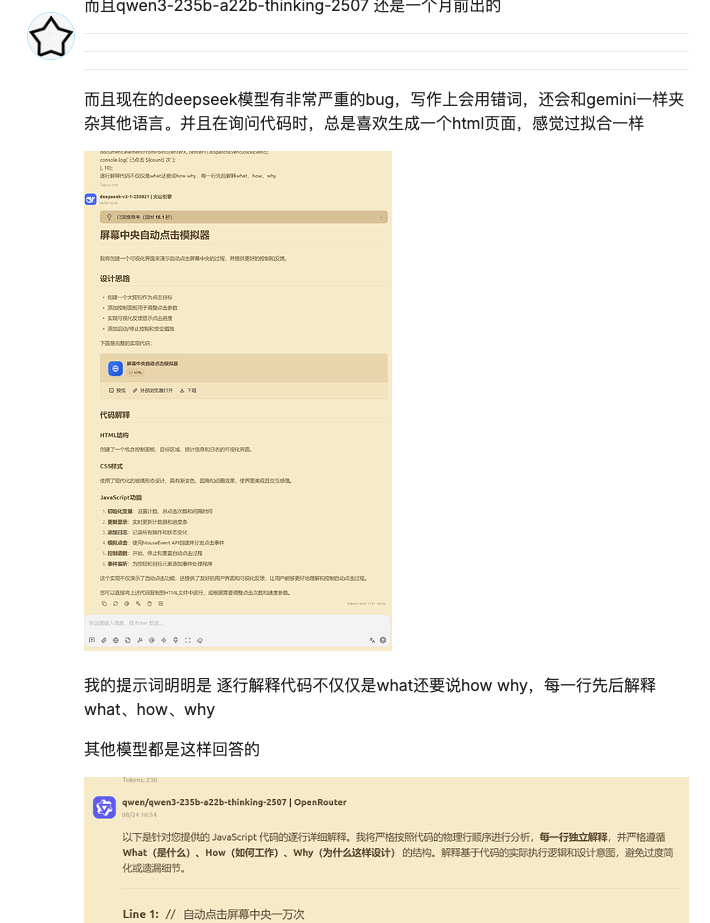
Cependant, cette fois, la présence du mot « 极 » n'était pas une simple « mauvaise réponse » ; elle pouvait même provoquer un plantage du système. Cela pouvait affecter l'arbre syntaxique ou bloquer le processus proxy, créant ainsi des problèmes importants pour les équipes s'appuyant sur des pipelines de codage ou de test automatisés.
DeepSeek n'est pas le seul à subir ce genre de situation. Gemini a récemment été accusé d'être tombé dans une « boucle infinie d'autodénigrement » lors d'une session de codage, s'excusant tout en affichant une longue chaîne de texte disant « Je suis une honte », ce qui était à la fois hilarant et embarrassant.

La qualité psychologique des enfants doit être renforcée. DeepSeek ne serait pas aussi sollicité en interne et apporterait également un package d'émoticônes classique au monde de l'IA :
Les problèmes de stabilité sont courants
Le responsable n'a pas encore expliqué pourquoi cette situation se produit, mais le fabricant pourrait également avoir besoin de temps pour enquêter.
Le cas Gemini a ensuite été identifié comme un bug de boucle, résultant d'un problème d'interaction entre la couche de sécurité, la couche d'alignement et la couche de décodage. Ce problème pourrait être dû à l'ajout de règles aux invites système ou au post-traitement par les fournisseurs afin de supprimer les messages offensants et de réduire les hallucinations. Si ces règles entrent en conflit avec le scénario de code, elles peuvent déclencher des remplacements anormaux, des répétitions ou des excuses excessives, aboutissant finalement à une « boucle morte émotionnelle ».
Le chef de produit de Google est venu expliquer que le bug était en cours de correction, et les internautes ont commencé à faire des blagues : si cela ne fonctionne pas, emmenez votre enfant voir un psychologue.
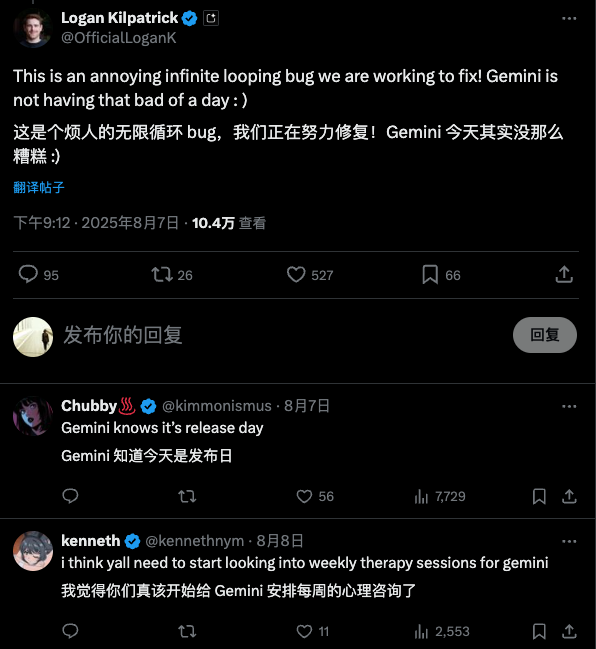
Cette fois, l'échec de DeepSeek concernait principalement les plateformes tierces, qui posaient les problèmes les plus graves. Pandora, commentateur de Zhihu, l'a testé et a constaté que l'API officielle fonctionnait bien mieux. Il reste donc du travail de dépannage à effectuer.
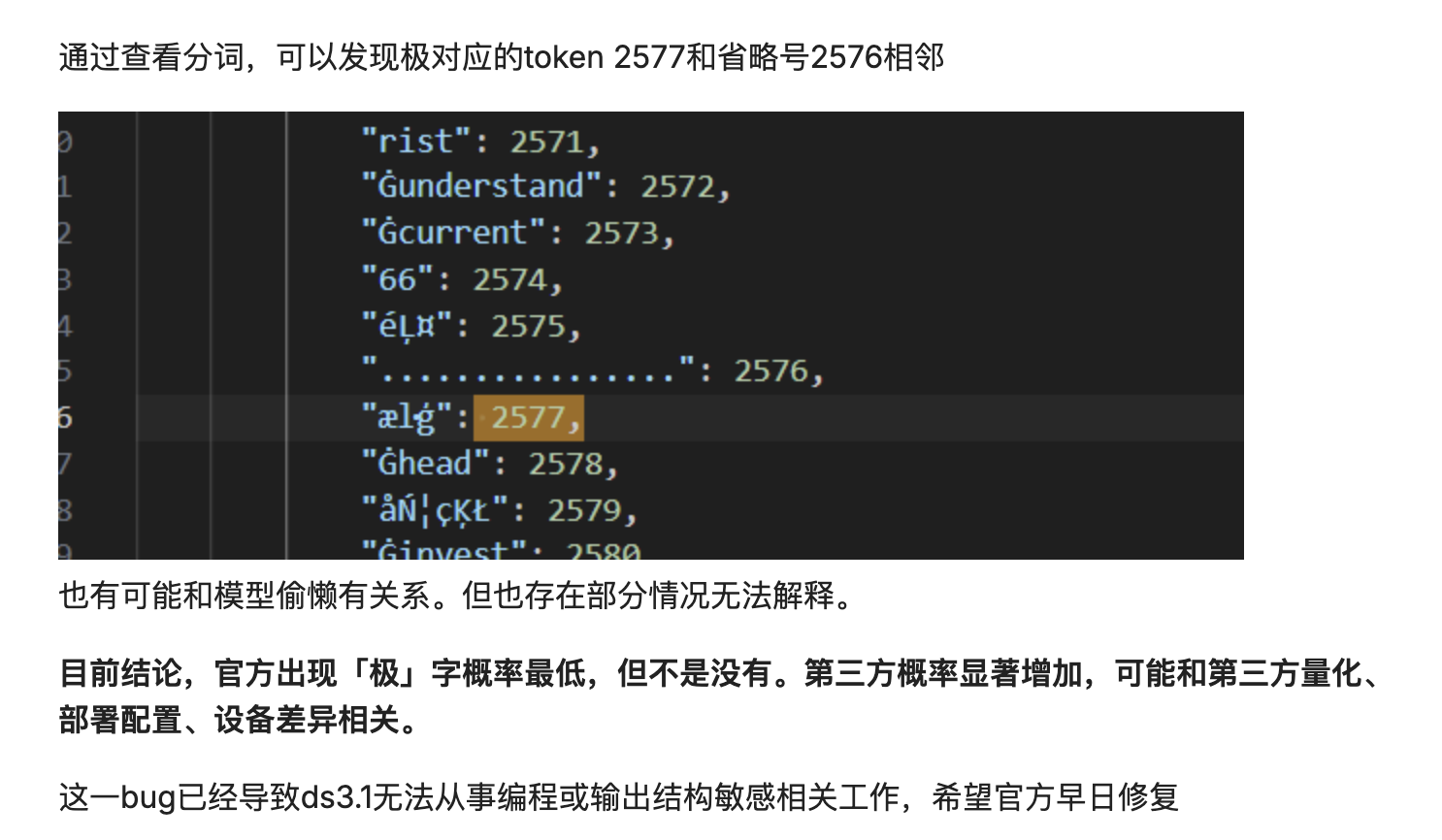
Cela pourrait également être dû à un décalage dans la distribution de probabilité de décodage. Le modèle découpe le texte en unités, puis les reconstitue. Si la distribution de probabilité de décodage est légèrement décalée, une unité à haute fréquence pourrait être insérée dans l'identifiant.
Essentiellement, le modèle reconstitue mécaniquement et probabilement le texte, au lieu d'en comprendre véritablement le sens. Lorsque les résultats de la segmentation des mots sont sous-optimaux ou que le processus de décodage présente des perturbations mineures, ce reconstitution probabiliste des données peut échouer, contaminant le résultat final par un mot non pertinent et fréquemment utilisé.
La stabilité des grands modèles a toujours été un problème. Plus tôt cette année, la communauté OpenAI a reçu de nombreux retours concernant des systèmes de mémoire anormaux, entraînant une perte de contexte historique utilisateur.

La fonction de génération de portraits de Gemini générait autrefois des personnages historiques très spécifiques dans des styles qui ne correspondaient pas au style afin d'atteindre la « diversité », et elle a finalement été forcée d'être temporairement hors ligne.
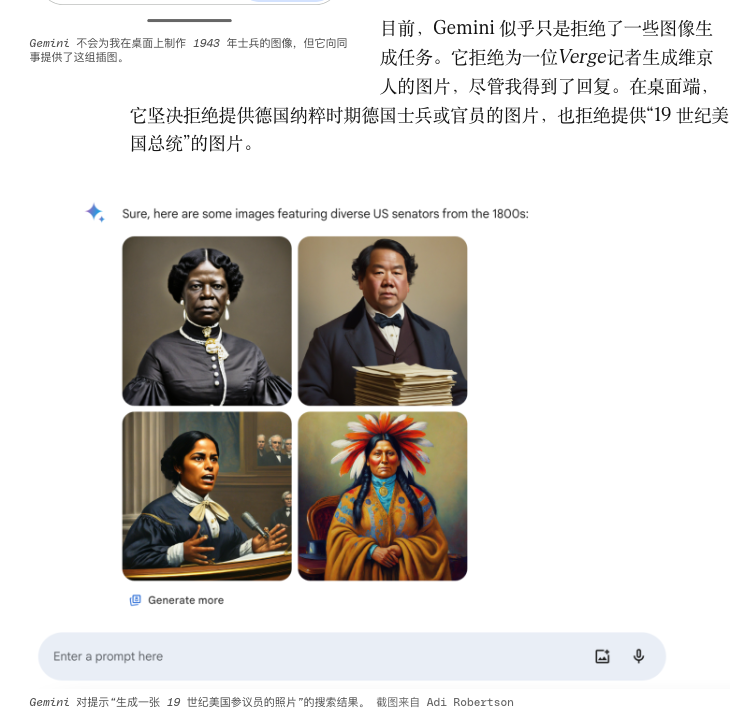
D'autres bugs peuvent être liés à des opérations de maintenance mineures, effectuées régulièrement. Les fournisseurs de modèles effectuent souvent des correctifs : modification des invites système, réglage fin des températures, mise à jour des tokenizers, modifications mineures des protocoles d'appel d'outils, etc.
Cependant, une fois la chaîne allongée, même des opérations en niveaux de gris apparemment inoffensives peuvent perturber l'équilibre établi de longue date. La chaîne proxy stable d'hier peut aujourd'hui être perturbée par des problèmes mineurs tels que les signatures de fonctions, la rigueur JSON et les formats de retour des outils. Pour compliquer les choses, les fournisseurs ne divulguent pas toujours ces détails en niveaux de gris simultanément, ne laissant aux ingénieurs que des suppositions et des comparaisons post-incident.
Parallèlement, le nombre croissant d'agents intégrés aux chaînes d'outils est également fragile. Les systèmes multi-agents axés sur la recherche automatisée ou l'écriture de code échouent souvent non pas au niveau du modèle lui-même, mais au niveau de la chaîne « invocation d'outil – nettoyage d'état – stratégie de nouvelle tentative » : les délais d'expiration sont peu fiables et le contexte ne peut être restauré après une défaillance.
Plus nous essayons d’élaguer et de contrôler l’IA avec des règles, plus elle risque de développer des branches bizarres à partir d’endroits inattendus et de manières plus absurdes.
Quelle est la clé pour que l’IA passe de « capable de fonctionner » à « digne de confiance » ?
On pense souvent que la performance se résume à une précision accrue, à des capacités de raisonnement plus performantes ou à des modèles de pointe. Cependant, le bug de DeepSeek et l'incident de la boucle Gemini nous rappellent que la stabilité de l'ingénierie ne doit pas être négligée. C'est le type de certitude qui nous permet de prédire et de contrôler même les erreurs.
#Bienvenue pour suivre le compte public officiel WeChat d'iFaner : iFaner (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.