
À quoi cela ressemble-t-il de connecter quatre Mac Studios haut de gamme et d’exécuter deux machines DeepSeek simultanément pour seulement 400 000 yuans ?

Il y a quelques mois, iFanr a déployé avec succès un modèle local large DeepSeek 671B (version quantifiée 4 bits) sur un Mac Studio équipé d'un processeur M3 Ultra. Si quatre Mac Studio haut de gamme équipés de processeurs M3 Ultra étaient connectés ensemble à l'aide d'outils open source pour former un « cluster d'IA de bureau », le potentiel d'inférence locale pourrait-il être encore plus élevé ?
C’est également le problème que tente de résoudre Exo Labs, une startup britannique.
Ne présumez pas que l’Université d’Oxford dispose d’un stock illimité de GPU
On pourrait penser qu’une grande université comme Oxford aurait plus de GPU qu’elle ne peut en utiliser, mais ce n’est pas du tout le cas.
Les fondateurs d'Exo Labs, Alex et Seth, sont diplômés de l'Université d'Oxford. Même dans une institution aussi prestigieuse, l'accès aux clusters de GPU nécessite des mois d'attente, et les demandes ne peuvent être déposées qu'une seule carte à la fois, ce qui rend le processus long et inefficace.
Ils se rendent compte que l’infrastructure d’IA actuelle, hautement centralisée, marginalise les chercheurs individuels et les petites équipes.
En juillet dernier, ils ont lancé leur première expérience, exécutant avec succès le modèle LLaMA sur deux MacBook Pro en tandem. Bien que les performances soient limitées, avec seulement trois jetons par seconde, elles ont suffi à démontrer la faisabilité de l'architecture Apple Silicon pour le raisonnement en IA distribuée.

Le véritable tournant a eu lieu avec la sortie du Mac Studio M3 Ultra. Ses 512 Go de mémoire unifiée, sa bande passante mémoire de 819 Go/s, son GPU à 80 cœurs et la capacité de transfert bidirectionnel de 80 Gbit/s du Thunderbolt 5 ont permis de créer des clusters d'IA locaux.
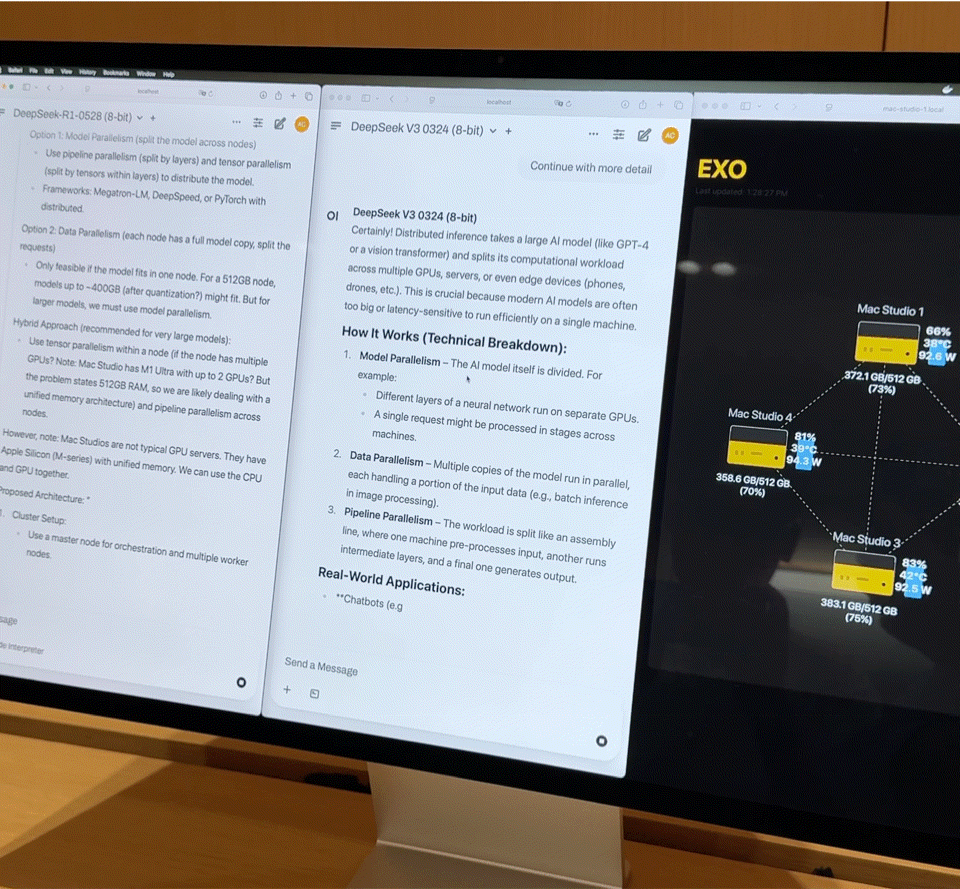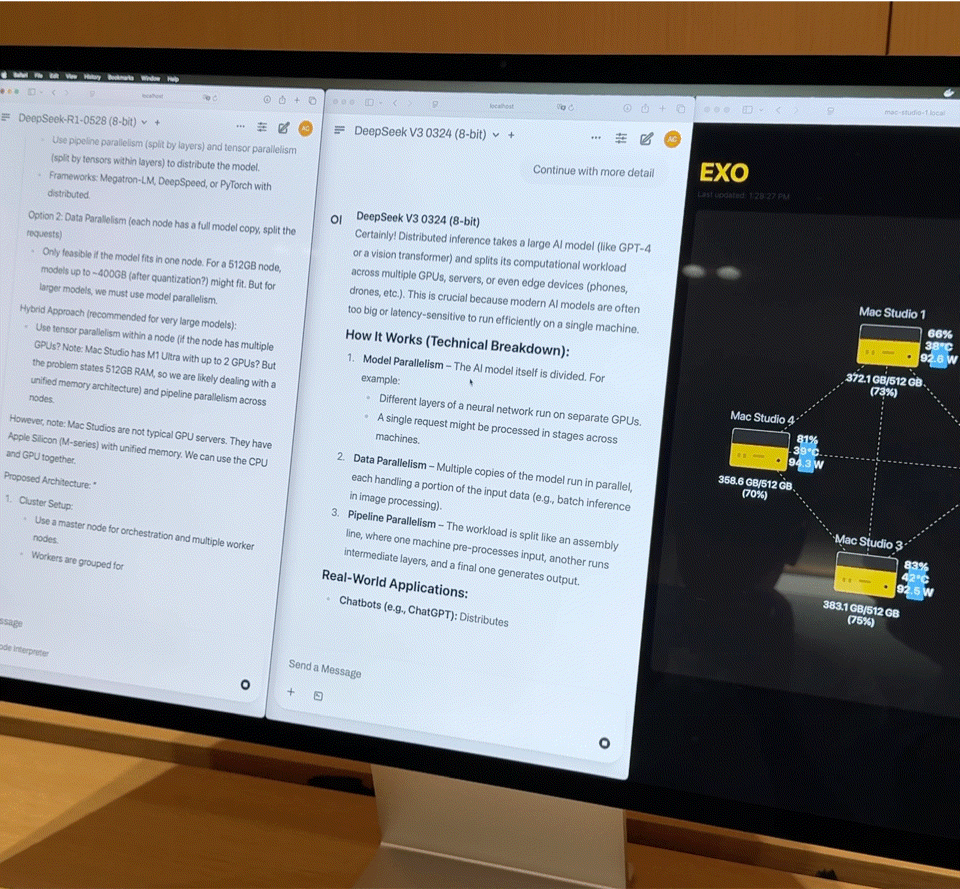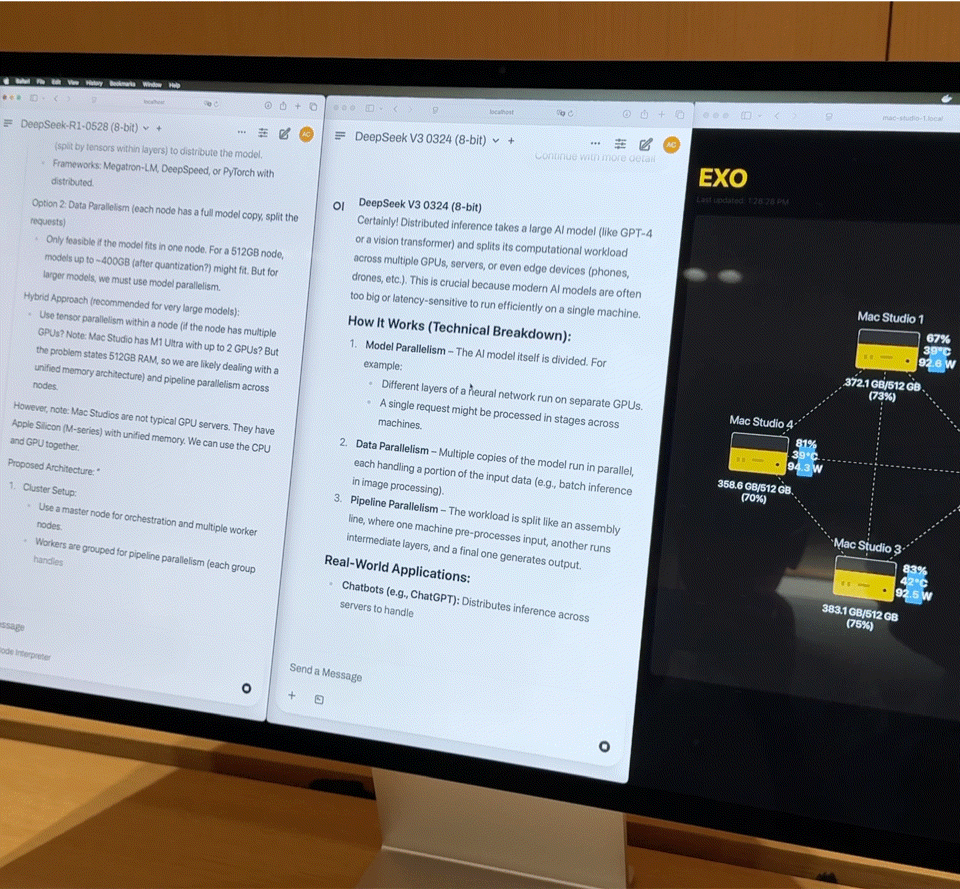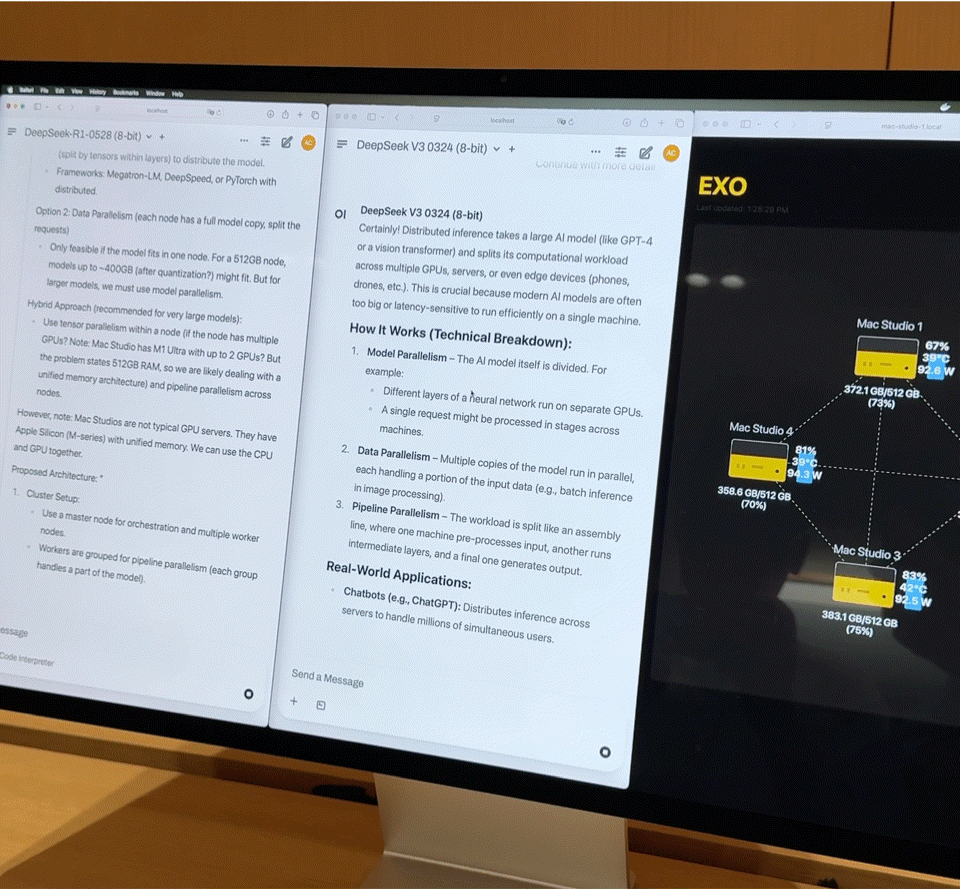
À quoi ressemble l’exécution simultanée de deux modèles de 67 milliards de paramètres ?
Après avoir connecté quatre Mac Studios haut de gamme équipés de processeurs M3 Ultra via Thunderbolt 5, les chiffres de performances sont assez impressionnants :
- Processeur 128 cœurs (32×4)
- 240 cœurs GPU (80×4)
- Mémoire unifiée de 2 To (512 Go x 4)
- La bande passante mémoire totale dépasse 3 To/s
Cette combinaison est quasiment équivalente à un petit supercalculateur domestique. Cependant, le matériel n'est que la base ; la clé pour exploiter pleinement sa puissance réside dans Exo, la plateforme de planification de modèles distribués développée par EXO Labs. Exo divise automatiquement le modèle en fonction de la mémoire et de la bande passante disponibles, et le déploie sur le nœud le plus approprié.
Sur place, Exo a démontré les capacités de base suivantes :
- Chargement de modèles volumineux : Un modèle DeepSeek complet avec quantification 8 bits nécessite plus de 700 Go de mémoire, bien au-delà de la capacité d'un seul Mac Studio. Exo répartit le modèle sur deux Mac Studios pour finaliser le chargement. Une fois activé, sa vitesse de frappe surpasse celle de la lecture humaine.
- Inférence parallèle : DeepSeek R1, également doté de 67 milliards de paramètres, a été chargé sur DeepSeek V3. Le système a immédiatement distribué R1 aux deux appareils restants, permettant ainsi l'inférence parallèle de deux grands modèles et l'interrogation simultanée de plusieurs utilisateurs.
- Document privé Q&R : Glissez-déposez un rapport financier d'entreprise au format PDF et le modèle effectuera l'intégration des connaissances et la Q&R localement. Il ne dépend d'aucune ressource cloud et les données sont entièrement privées et contrôlables.
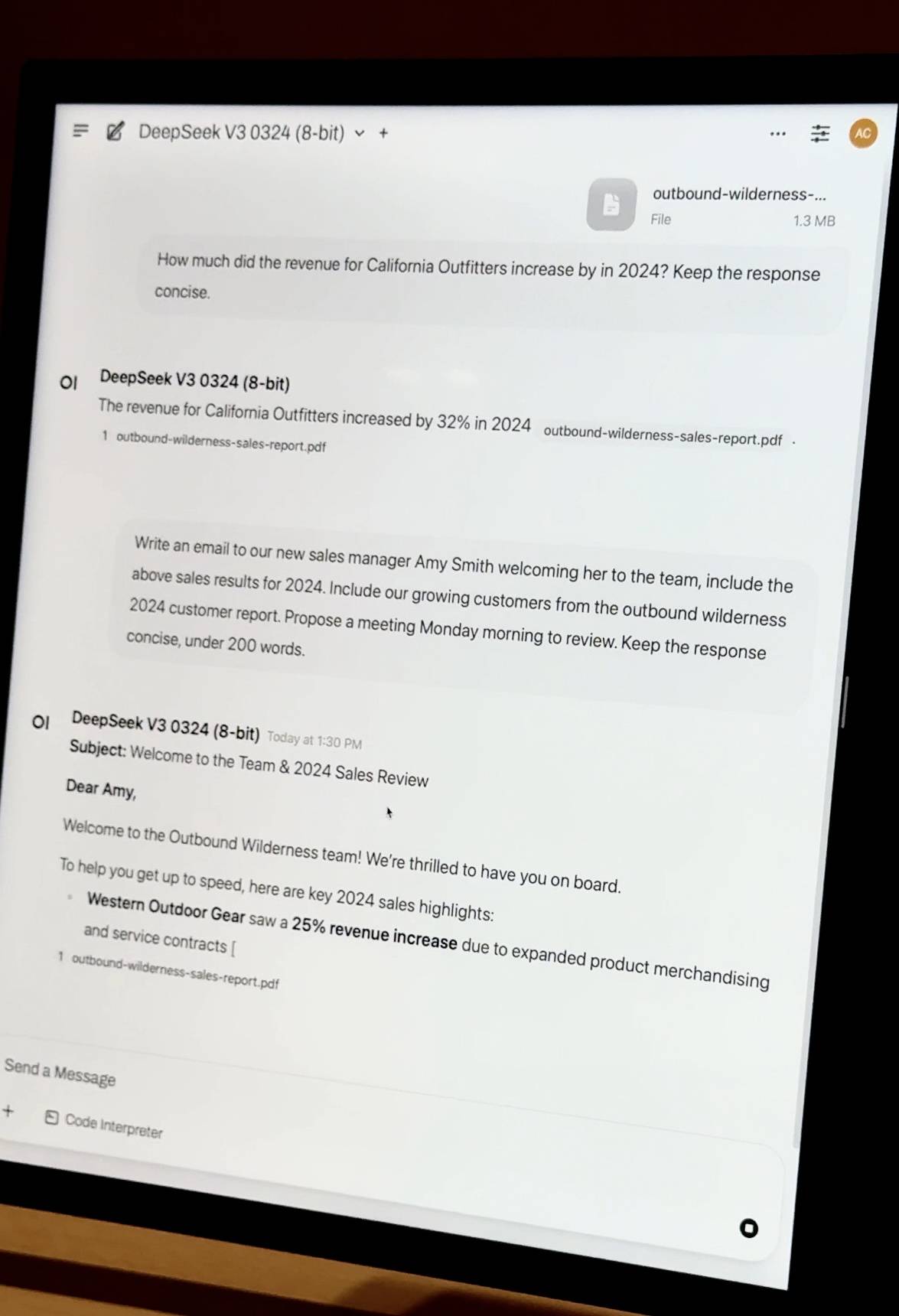
- Réglages précis et légers : les entreprises disposant de milliers de documents internes peuvent effectuer des réglages précis localement grâce aux technologies QLoRA et LoRA. Le réglage précis d'une seule machine peut prendre plusieurs jours, mais grâce aux capacités de planification en cluster d'Exo, les tâches de formation peuvent être accélérées de manière linéaire, réduisant ainsi considérablement les coûts liés au temps.
Énorme différence de coût
iFanr a observé le diagramme de topologie dans les coulisses et a constaté que même si les quatre machines étaient dans un état de charge élevée en même temps, la consommation électrique de l'ensemble du système était toujours contrôlée à moins de 400 W et il n'y avait presque aucun bruit de ventilateur pendant le fonctionnement.
Pour obtenir les mêmes performances avec des solutions de serveur traditionnelles, il faut déployer au moins 20 cartes graphiques A100. Le coût du serveur et de l'équipement réseau dépasse les 2 millions de RMB, la consommation électrique atteint plusieurs kilowatts et une salle informatique et un système de refroidissement indépendants sont nécessaires.
Les puces Apple ont trouvé de manière inattendue une nouvelle position dans la vague de l'IA

Le Mac Studio M3 Ultra est proposé à partir de 32 999 yuans et est équipé de 96 Go de mémoire unifiée, tandis que la version haut de gamme de 512 Go est certes onéreuse. Cependant, d'un point de vue technique, les avantages apportés par l'architecture mémoire unifiée sont révolutionnaires.
Lorsqu'Apple a conçu la puce M, elle était principalement destinée à la création personnelle, économe en énergie et performante. Cependant, des fonctionnalités telles que la mémoire unifiée, un GPU à large bande passante et l'agrégation multi-chemins Thunderbolt ont trouvé, de manière inattendue, un nouveau créneau à l'ère de l'IA.
Les GPU traditionnels, même les cartes graphiques haut de gamme pour stations de travail, ne disposent généralement que de 96 Go de mémoire vidéo. La mémoire unifiée d'Apple permet au CPU et au GPU de partager la même mémoire à large bande passante, éliminant ainsi les transferts de données fréquents entre différents niveaux de stockage. Ceci est crucial pour l'inférence de modèles à grande échelle.
Bien entendu, la solution EXO présente également un positionnement distinct. Elle n'est pas conçue pour concurrencer directement le H100, ni pour entraîner la prochaine génération de GPT. Elle est plutôt conçue pour résoudre des problèmes d'application pratiques : exécuter vos propres modèles, protéger vos données et effectuer les ajustements et optimisations nécessaires.
Si H100 est le roi au sommet de la pyramide, alors Mac Studio devient le couteau suisse entre les mains des petites et moyennes équipes.
#Bienvenue pour suivre le compte public officiel WeChat d'iFaner : iFaner (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.