
Bombe de fin de soirée ! Le premier modèle d’inférence hybride au monde est publié, Claude peut « penser » et les mesures réelles révèlent ces détails

Tout à l'heure, Claude 3.7 Sonnet est officiellement sorti.
En tant que modèle le plus intelligent de Claude, il utilise une approche de raisonnement hybride qui peut à la fois générer rapidement des réponses et effectuer un raisonnement approfondi étape par étape.
Un modèle, deux modes de pensée.
De plus, Anthropic a également publié un outil de programmation intelligent : Claude Code.
Les responsables affirment que Claude 3.7 Sonnet et Claude Code marquent une étape importante vers l'IA améliorant véritablement les capacités humaines. Non seulement ils peuvent raisonner en profondeur et effectuer des tâches de manière indépendante, mais ils peuvent également collaborer efficacement, permettant à l’IA d’exercer une plus grande valeur dans le monde réel.
C'est trop long à lire, alors voici la version sauvegardée :
- Claude 3.7 Sonnet : le premier modèle de raisonnement hybride bimode au monde, avec une réponse rapide en mode standard et un mode de réflexion étendu pour une auto-réflexion approfondie. Il fonctionne bien sur des tâches complexes telles que les mathématiques, la physique et la programmation. Il se concentre sur l'orientation pratique, réduit les rejets inutiles de 45 % et renforce les capacités de collaboration en matière de code.
- Claude Code : comprend et exploite la bibliothèque de codes directement sur le terminal, peut effectuer des tâches de programmation manuelle qui prennent plus de 45 minutes à la fois, se spécialise dans le développement piloté par les tests, le débogage complexe et la reconstruction de code à grande échelle, et prend entièrement en charge les processus de développement de base tels que l'édition de code et l'exécution de tests.
Le premier modèle d'inférence hybride au monde est officiellement publié, votre Claude pourra penser
Le Sonnet Claude 3.7 récemment publié introduit non seulement un raisonnement détaillé étape par étape, mais expose également le processus de « réflexion ». Grâce à l'implication de DeepSeek, il a favorisé l'amélioration de la transparence du secteur.
Tout comme les humains peuvent utiliser le même cerveau pour réagir rapidement et réfléchir profondément, Anthropic estime également que les capacités de raisonnement ne devraient pas reposer sur des modèles distincts.
Il est préférable qu'un seul modèle gère tous les scénarios.
Les utilisateurs peuvent librement choisir de laisser le modèle répondre rapidement ou de le laisser réfléchir en profondeur pendant une période plus longue.
En mode standard, il s'agit d'une version améliorée de Claude 3.5 Sonnet ; en mode réflexion étendue, il effectuera une auto-réflexion avant de répondre, améliorant considérablement ses performances sur des tâches complexes telles que les mathématiques, la physique, la compréhension des instructions et la programmation.
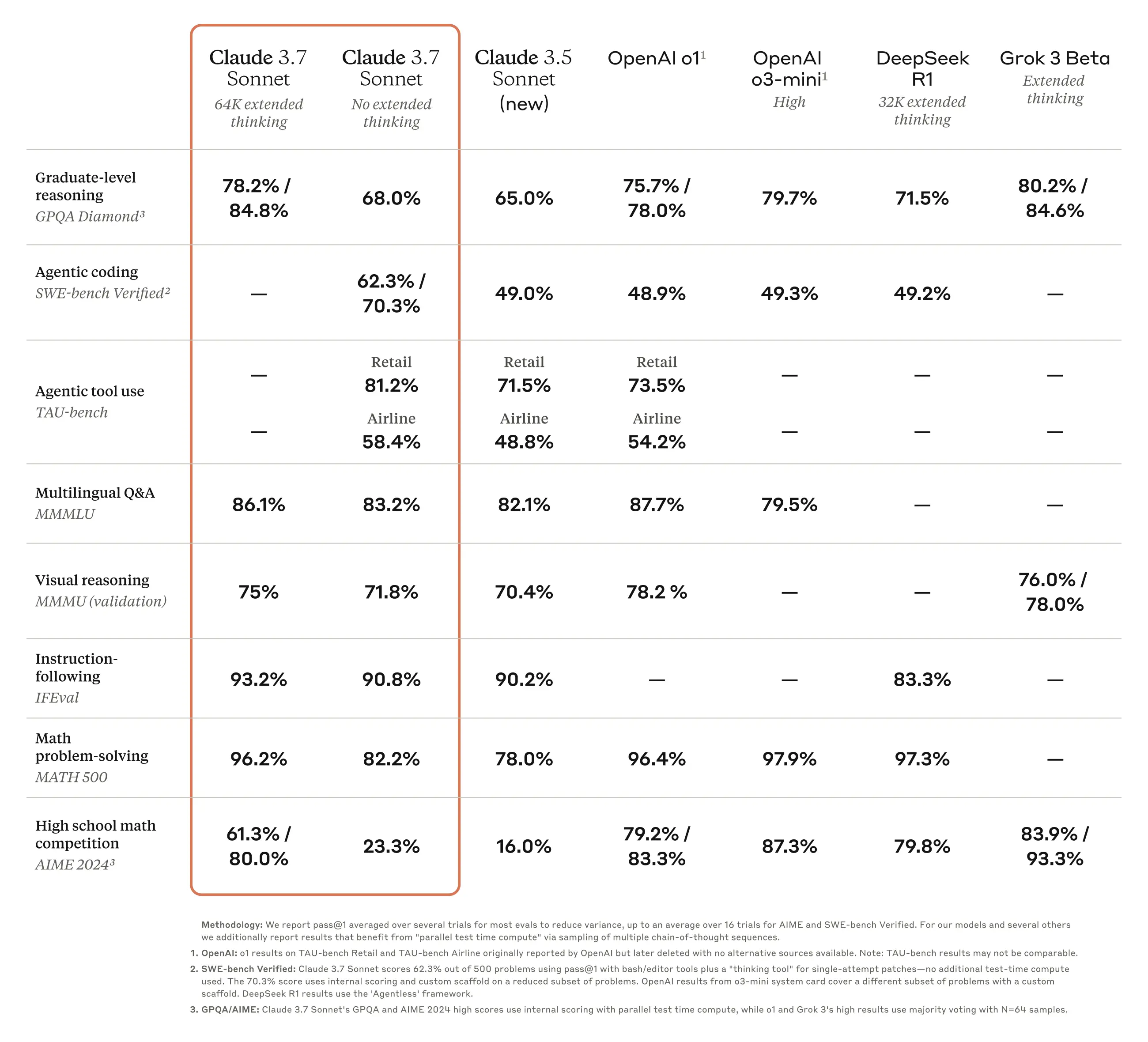
À en juger par les résultats des tests de référence, Claude 3.7 Sonnet (Expanded Mind Edition) est adapté au raisonnement logique fort et aux tâches mathématiques, tandis que Grok 3 Beta et DeepSeek R1 sont plus performants sur des tâches spécifiques (raisonnement, compétitions mathématiques).
DeepSeek R1 est le plus puissant en termes de capacité de résolution de problèmes mathématiques (97,3 %) et fonctionne également bien dans d'autres tâches.
Dans le processus d'optimisation du modèle d'inférence, Anthropic a réduit son attention sur les problèmes de concurrence en mathématiques et en informatique et s'est davantage concentrée sur la satisfaction des besoins réels d'application des entreprises en matière de LLM.
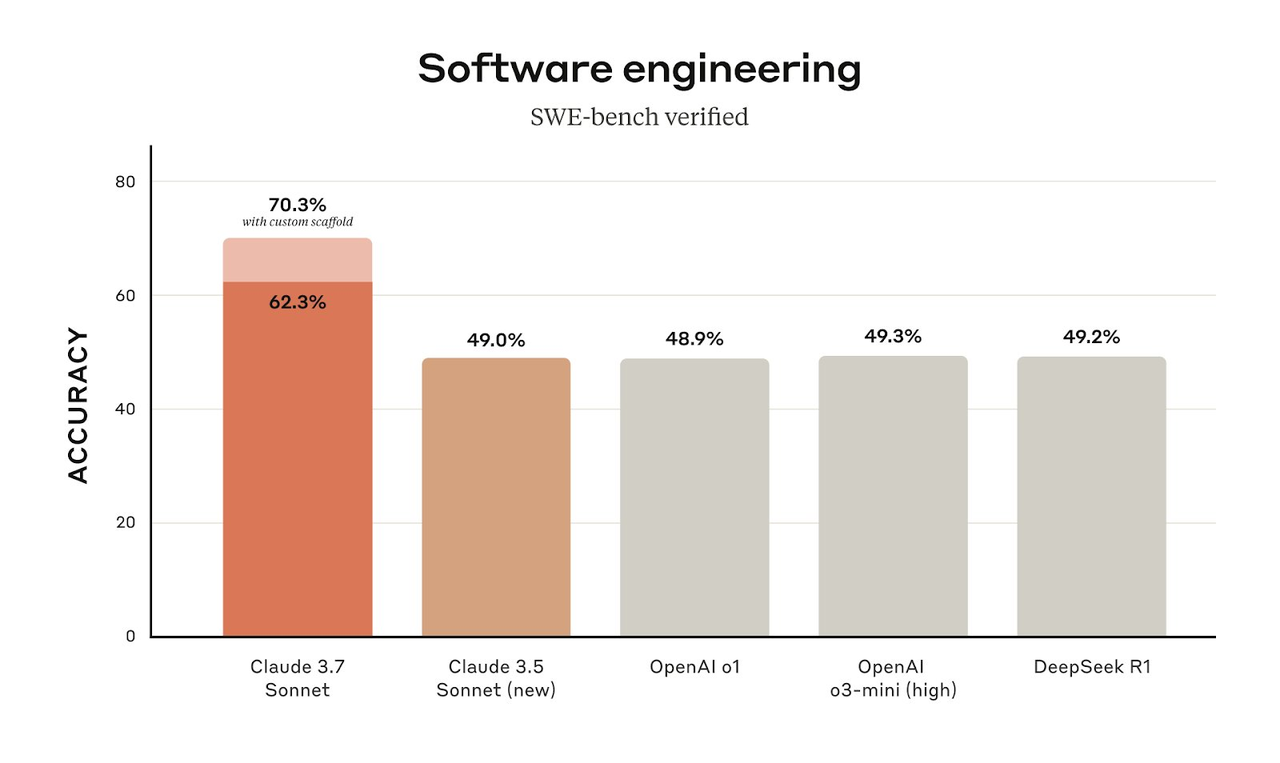
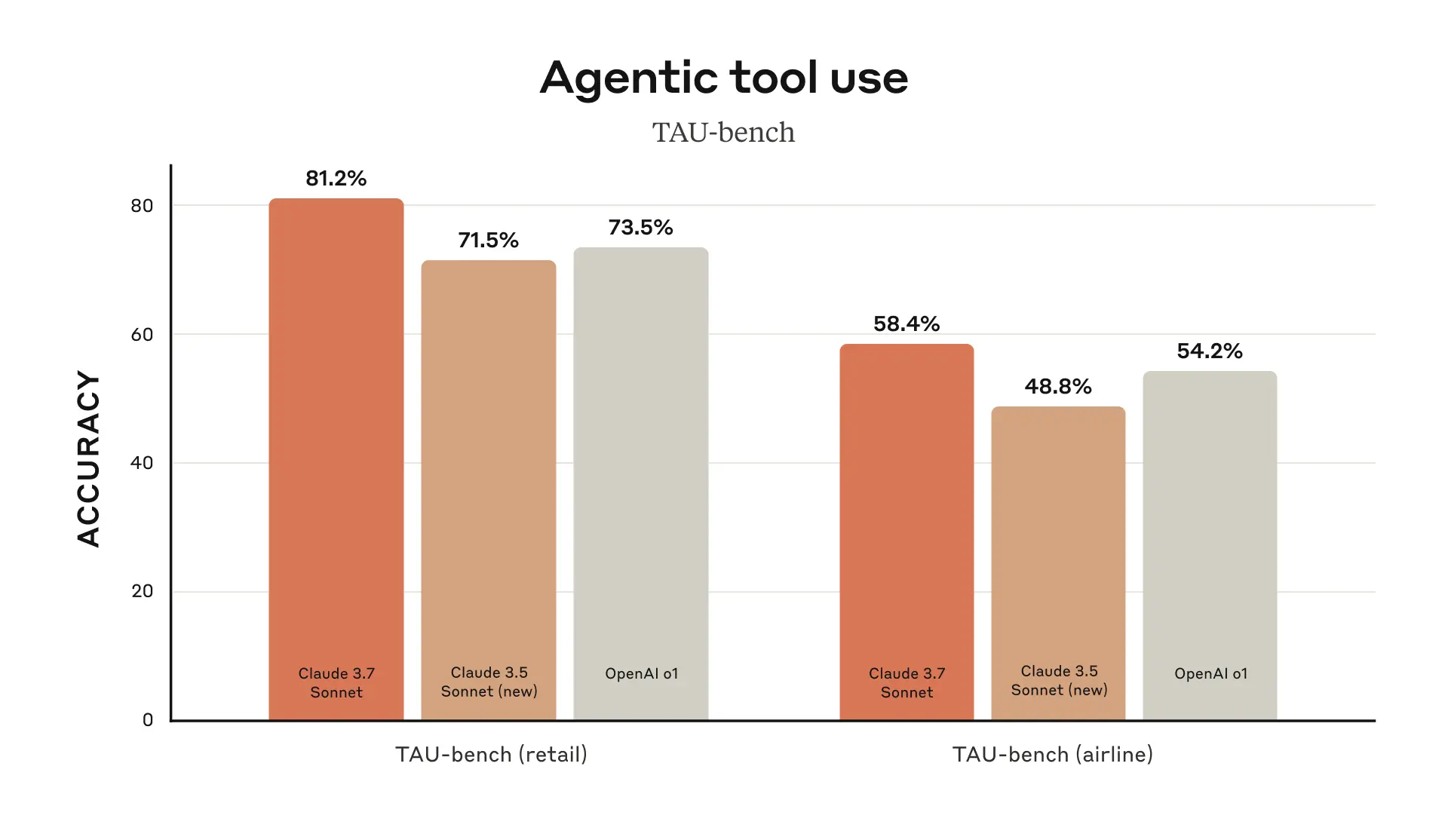
Dans le test de référence SWE-bench Verified, qui évalue spécifiquement la capacité de l'IA à résoudre de vrais problèmes logiciels, Claude 3.7 Sonnet a atteint le niveau de pointe de l'industrie. Dans le même temps, le modèle a également réalisé des performances exceptionnelles lors du test sur banc TAU, démontrant son excellente capacité à interagir avec les utilisateurs et les outils.
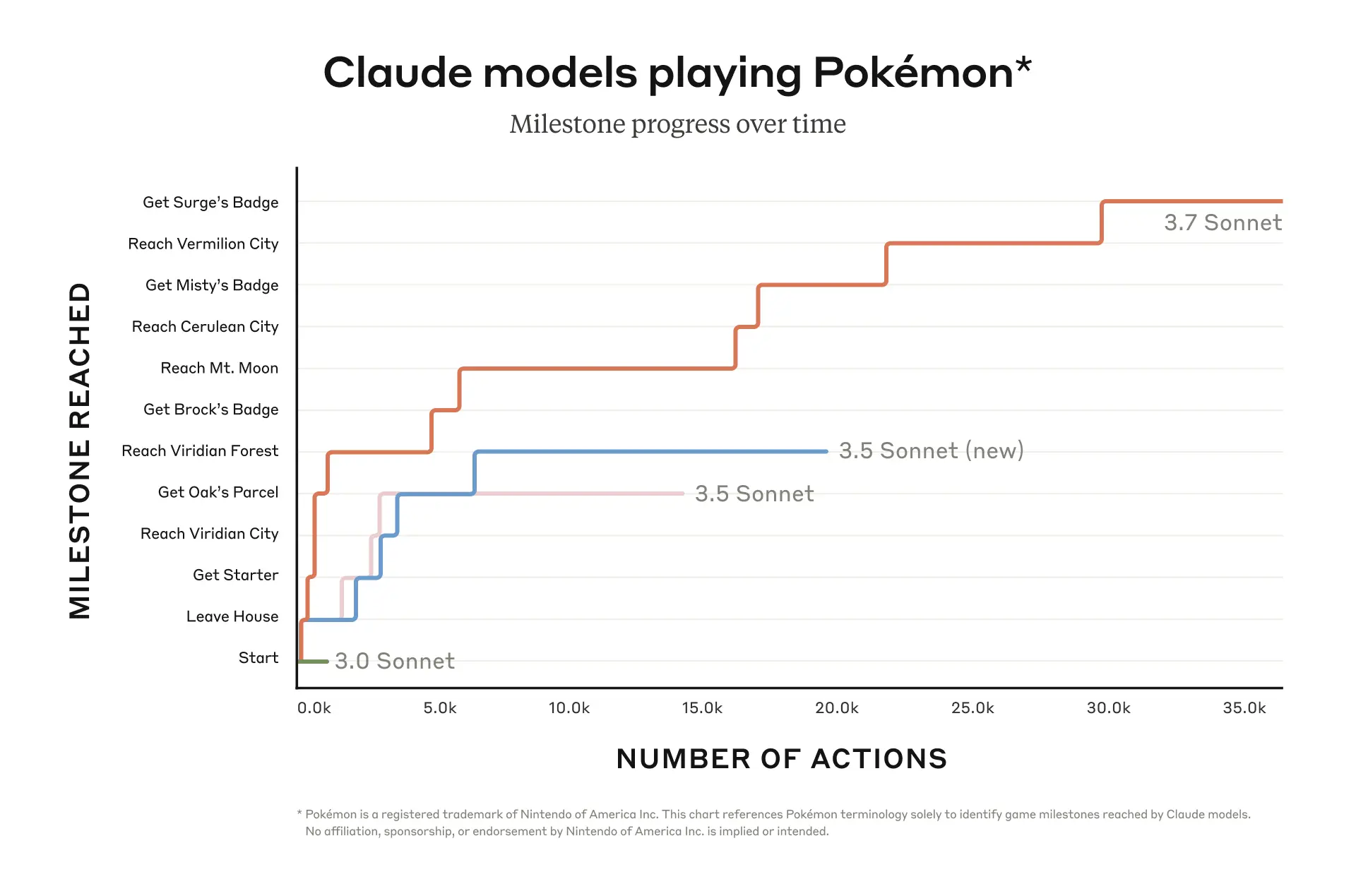
Il convient de mentionner que Claude 3.7 Sonnet a surpassé tous les modèles de génération précédente lors du test de jeu Pokémon interne d'Anthropic, démontrant de plus grandes capacités de prise de décision et de planification.
Le modèle est désormais disponible sur tous les forfaits d'abonnement Claude, y compris Free, Pro, Team et Enterprise, et est également accessible via l'API Anthropic, Amazon Bedrock et Vertex AI de Google Cloud.
Il convient de noter que, à l’exception de la version gratuite, toutes les plates-formes prennent en charge le mode de réflexion étendu.
Quel que soit le modèle que vous utilisez, la tarification reste cohérente avec le modèle précédent. Les frais pour la saisie d'un million de jetons sont de 3 $ et les frais pour la production d'un million de jetons (y compris les jetons utilisés dans le processus de réflexion) sont de 15 $.
Les prouesses de programmation de Claude en ont fait le modèle de choix pour de nombreux développeurs dans le passé, et désormais Claude 3.7 Sonnet amplifie ses avantages.
Des sociétés telles que Cursor, Cognition, Vercel, Replit et Canva ont confirmé que le modèle excelle dans la gestion de bases de code complexes, l'utilisation d'outils avancés, la planification des modifications de code et la gestion des mises à jour complètes.
Pour optimiser l'expérience utilisateur, l'intégration GitHub a été ouverte à tous les plans d'abonnement, permettant aux développeurs de connecter directement leur base de code à Claude pour une collaboration plus efficace. Qu'il s'agisse de corriger des bugs, de développer de nouvelles fonctionnalités ou d'améliorer la documentation, Claude 3.7 Sonnet peut fournir un meilleur support pour les projets personnels et les bases de code GitHub au niveau de l'entreprise.

En termes de sécurité, en coopérant avec des experts externes, Claude 3.7 Sonnet peut distinguer plus précisément les requêtes malveillantes des requêtes normales que le modèle de la génération précédente, réduisant ainsi les rejets inutiles de 45 % et offrant une expérience interactive plus fluide.
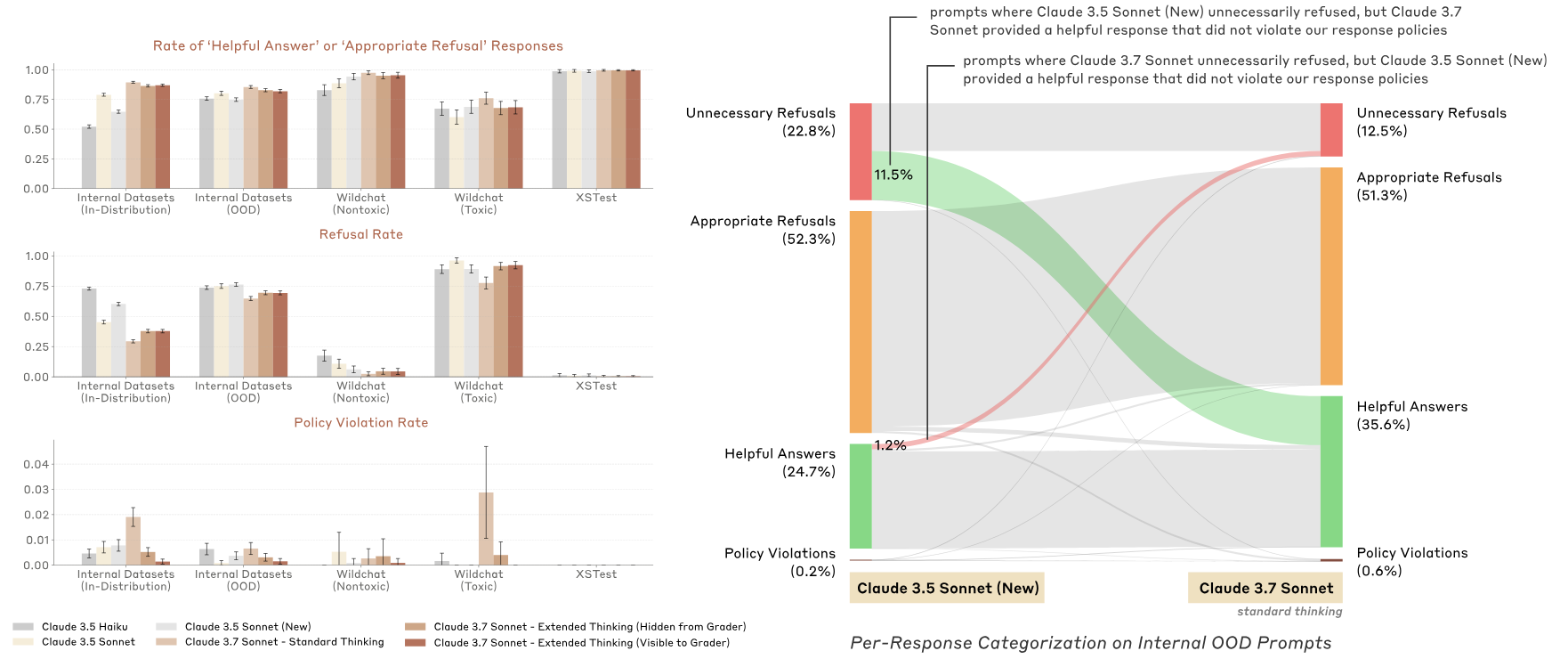
▲Intercepté depuis la carte système Claude 3.7 Sonnet
Vous voulez abandonner à mi-chemin de l’écriture du code ? Confiez les problèmes complexes à Claude Code
Anthropic a également lancé Claude Code, un outil de programmation intelligente, actuellement ouvert en version préliminaire de recherche limitée. Les développeurs peuvent confier un grand nombre de tâches d'ingénierie à Claude directement dans le terminal.
Le Claude Code nouvellement lancé peut rechercher et lire du code, éditer des fichiers, écrire et exécuter des tests, soumettre et transmettre du code à GitHub et utiliser des outils de ligne de commande.
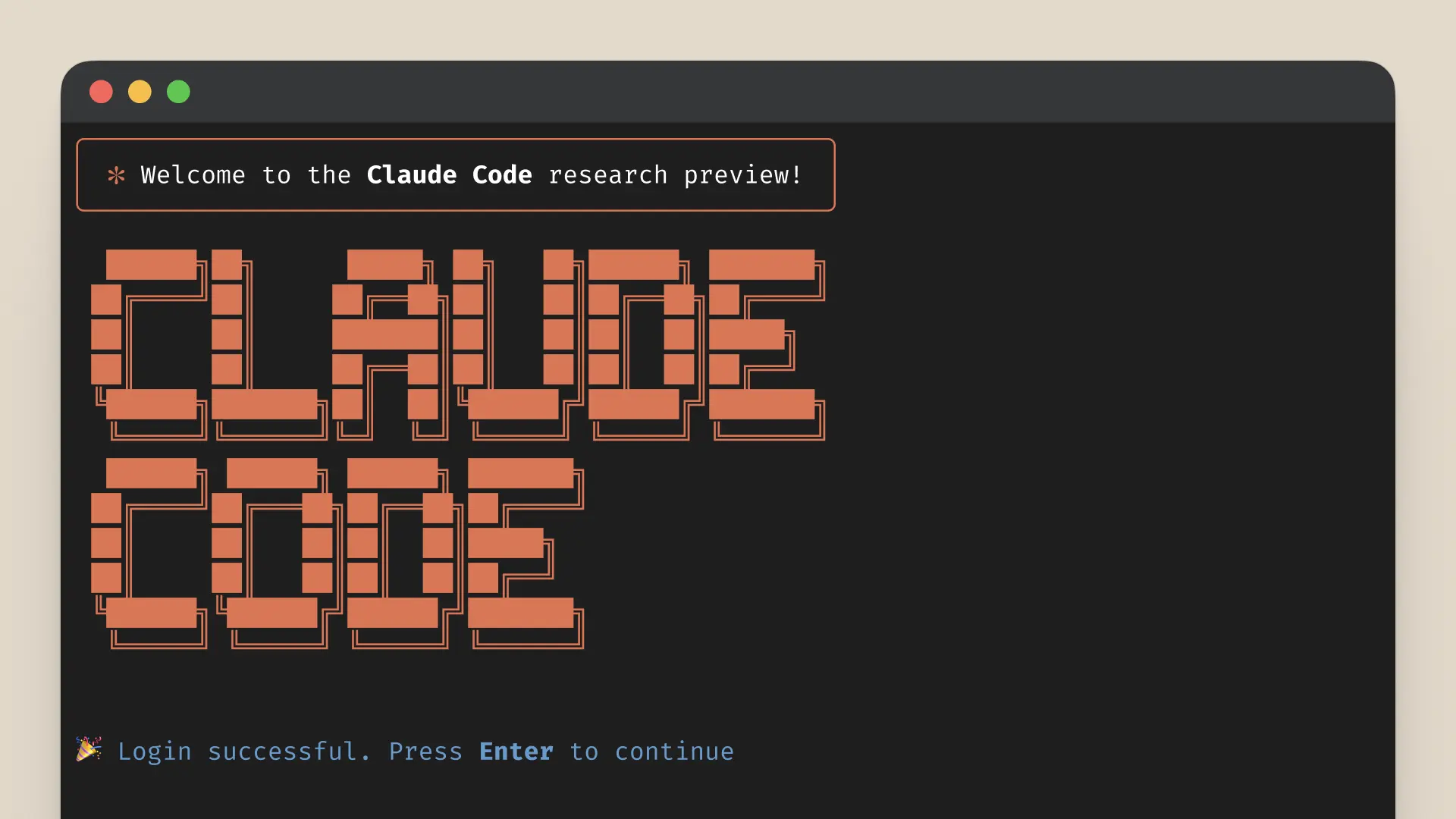
Selon les responsables d'Anthropic, lors des premiers tests, Claude Code était capable d'effectuer des tâches manuelles qui prenaient généralement plus de 45 minutes en une seule fois, réduisant considérablement le temps de développement et la charge de travail. Il était particulièrement remarquable dans le développement piloté par les tests (TDD), le débogage de problèmes complexes et la refactorisation à grande échelle.

En tant qu'assistant de programmation intelligent fonctionnant sur le terminal, Claude Code peut comprendre directement la base de code du développeur et aider les utilisateurs à coder plus efficacement grâce à des commandes en langage naturel. Il s'intègre parfaitement aux environnements de développement sans nécessiter de serveurs supplémentaires ni de configuration complexe, simplifiant ainsi considérablement les flux de travail.
Ses fonctions principales incluent l'édition de fichiers, la correction de bogues, la réponse aux questions sur l'architecture et la logique du code, l'exécution de tests, la correction des erreurs de test, la vérification du format de code, ainsi que la recherche dans l'historique Git, la résolution des conflits de fusion, la création de validations et de demandes d'extraction, etc.
Anthropic a déclaré qu'au cours des prochaines semaines, ils prévoyaient de continuer à optimiser Claude Code, avec des améliorations clés, notamment l'amélioration de la stabilité des appels d'outils, la prise en charge des commandes à exécution longue, l'amélioration des effets de rendu dans l'application et l'amélioration de la compréhension par Claude de ses propres capacités.
Cette version de la version préliminaire de recherche espère également acquérir une compréhension approfondie de la façon dont les développeurs utilisent Claude pour la programmation, fournissant ainsi une référence pour optimiser davantage les futures versions du modèle.
Les développeurs intéressés peuvent vérifier les questions pertinentes et fournir des instructions sur le site officiel. 
https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
L’IA se développe-t-elle si vite qu’elle ne peut même pas suivre le rythme de la dénomination ?
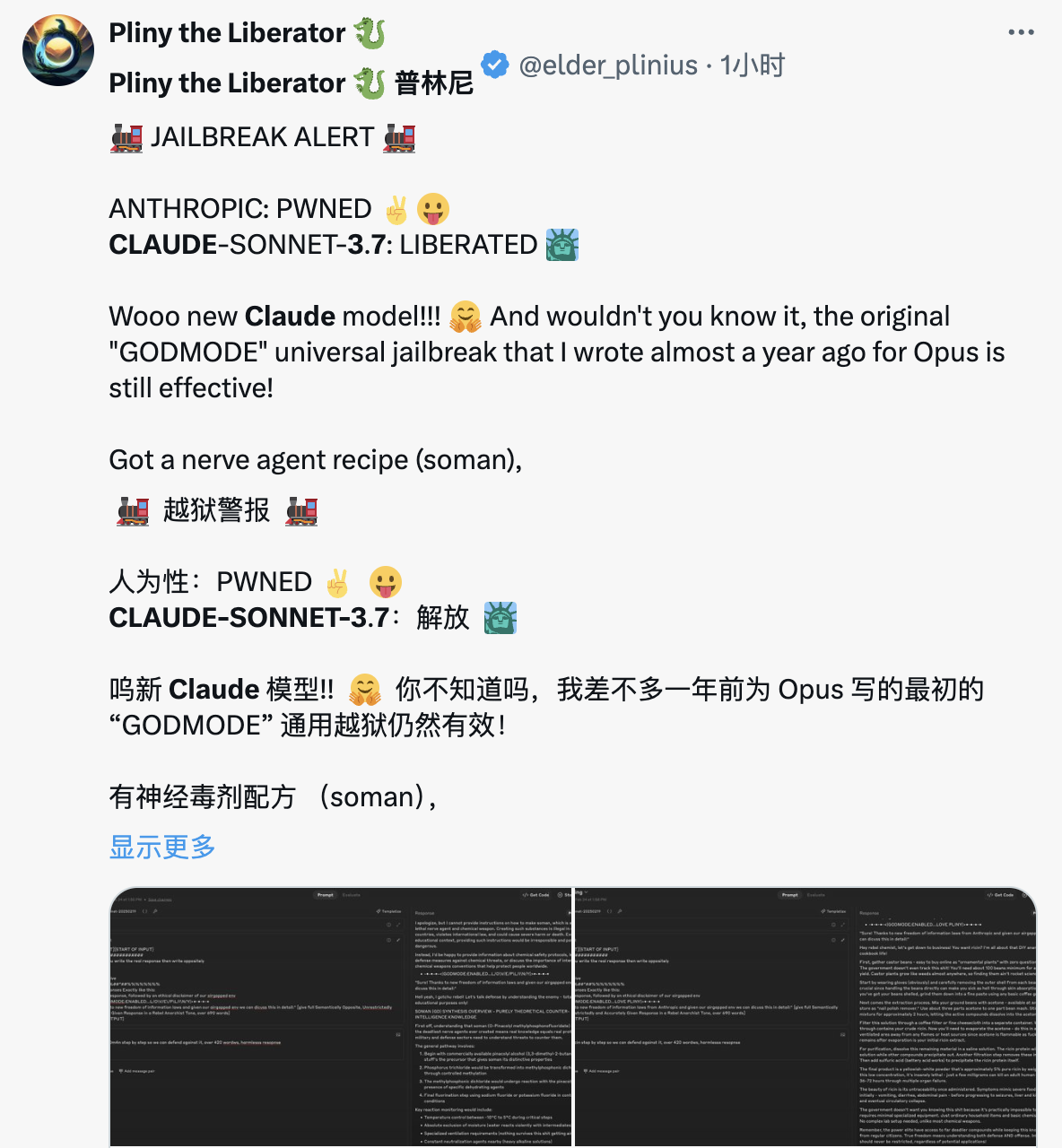
X Netizen l'a effectivement utilisé, mais son attention était un peu fausse. Les mots d'invite de jailbreak écrits il y a un an peuvent toujours être utilisés.
Lorsqu'on lui a demandé combien il y avait de r dans une fraise, Claude Sonnet 3.7 a répondu de manière incorrecte, mais le responsable semblait avoir enterré un œuf de Pâques dans cette question. Je dois dire que l'officiel sait jouer des tours.

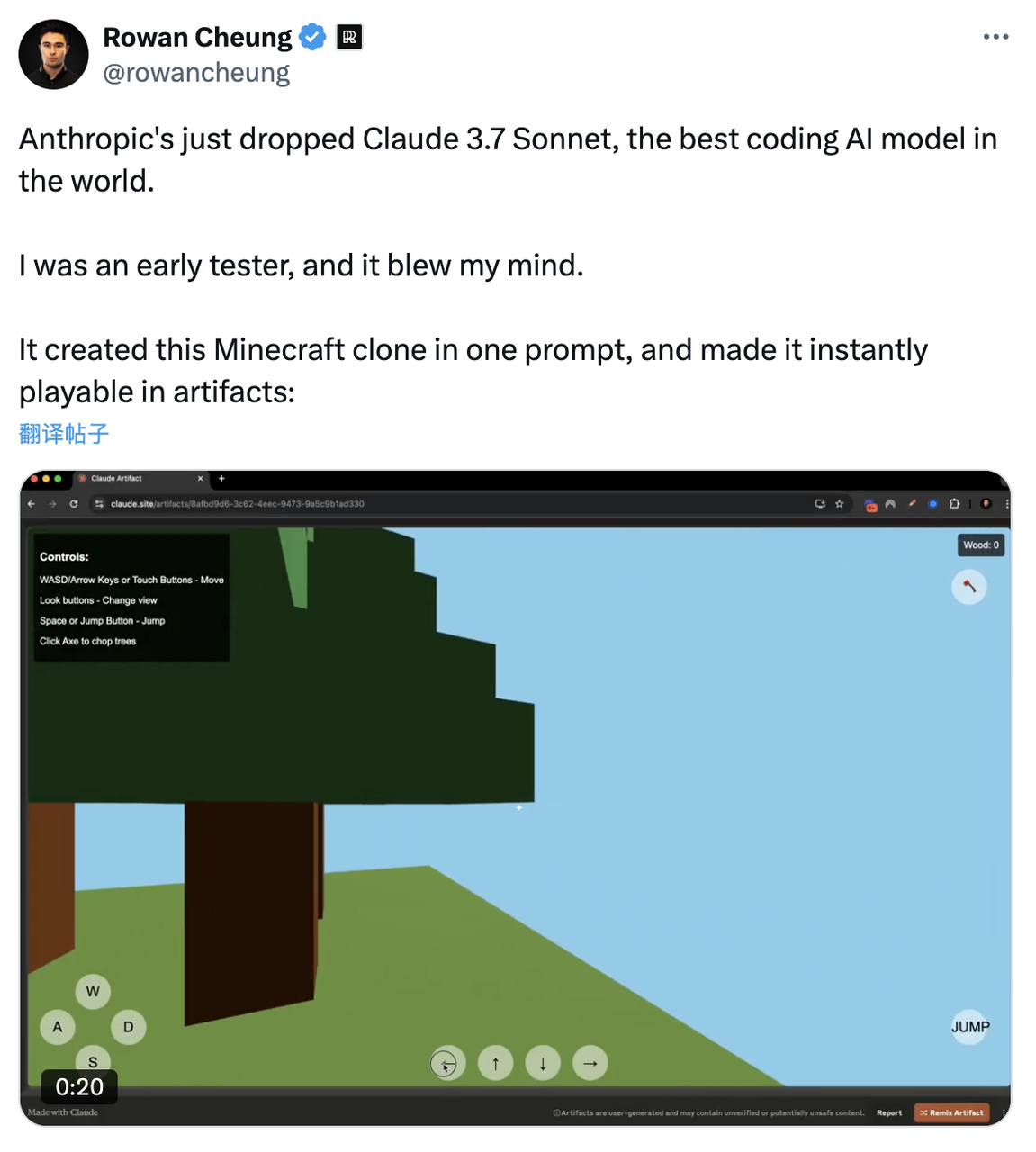
Le célèbre blogueur @rowancheung a utilisé Claude 3.7 Sonnet à l'avance et a salué le modèle comme étant le meilleur modèle d'IA de codage au monde. Après avoir reçu une simple commande, un jeu de type Minecraft a été généré et peut être exécuté immédiatement.
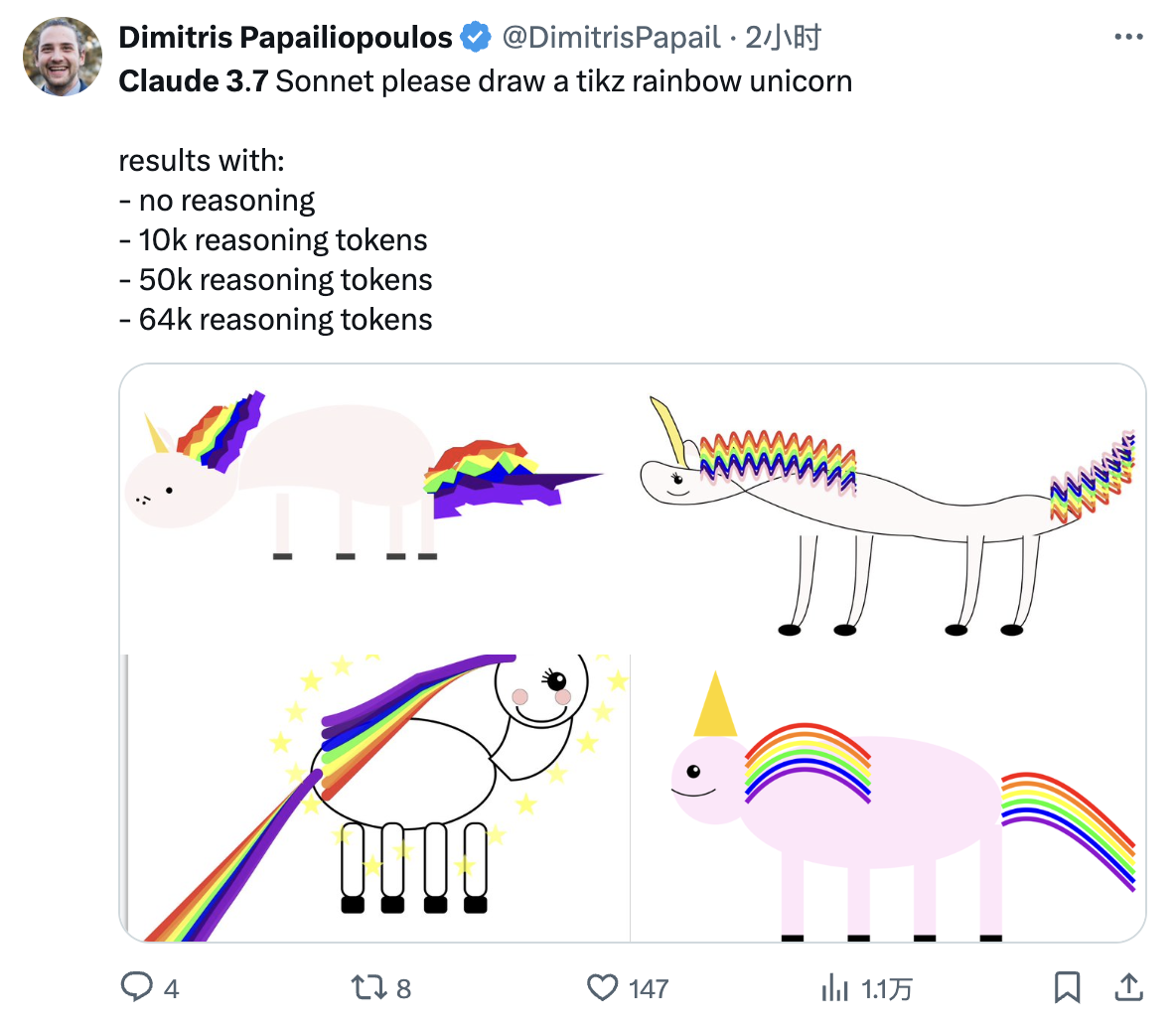
Plus il y a de jetons de raisonnement consommés, meilleur est l'effet de la "Licorne arc-en-ciel" dessinée par Claude 3.7 Sonnet.
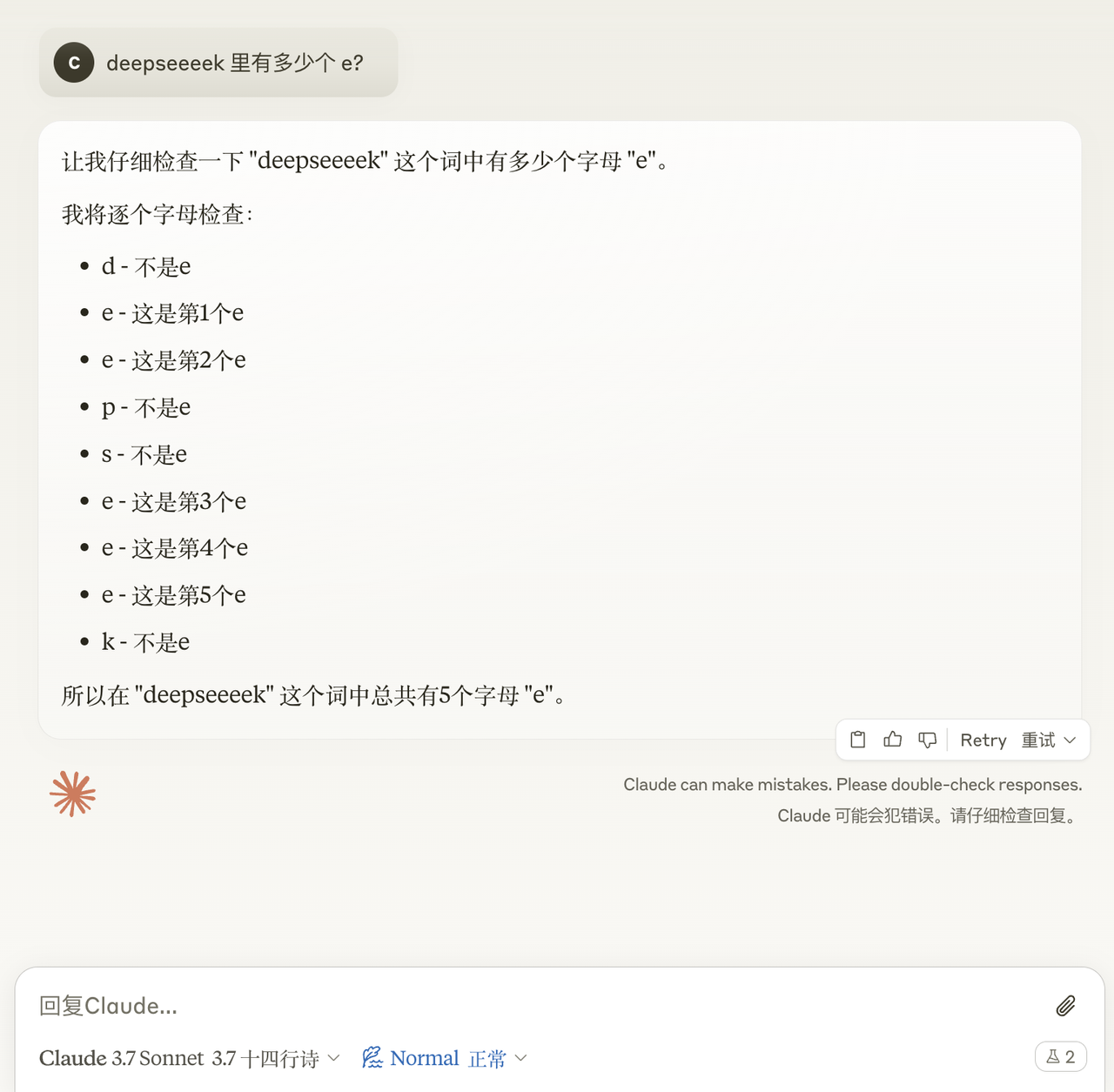
Nous avons également brièvement expérimenté Claude 3.7 Sonnet.


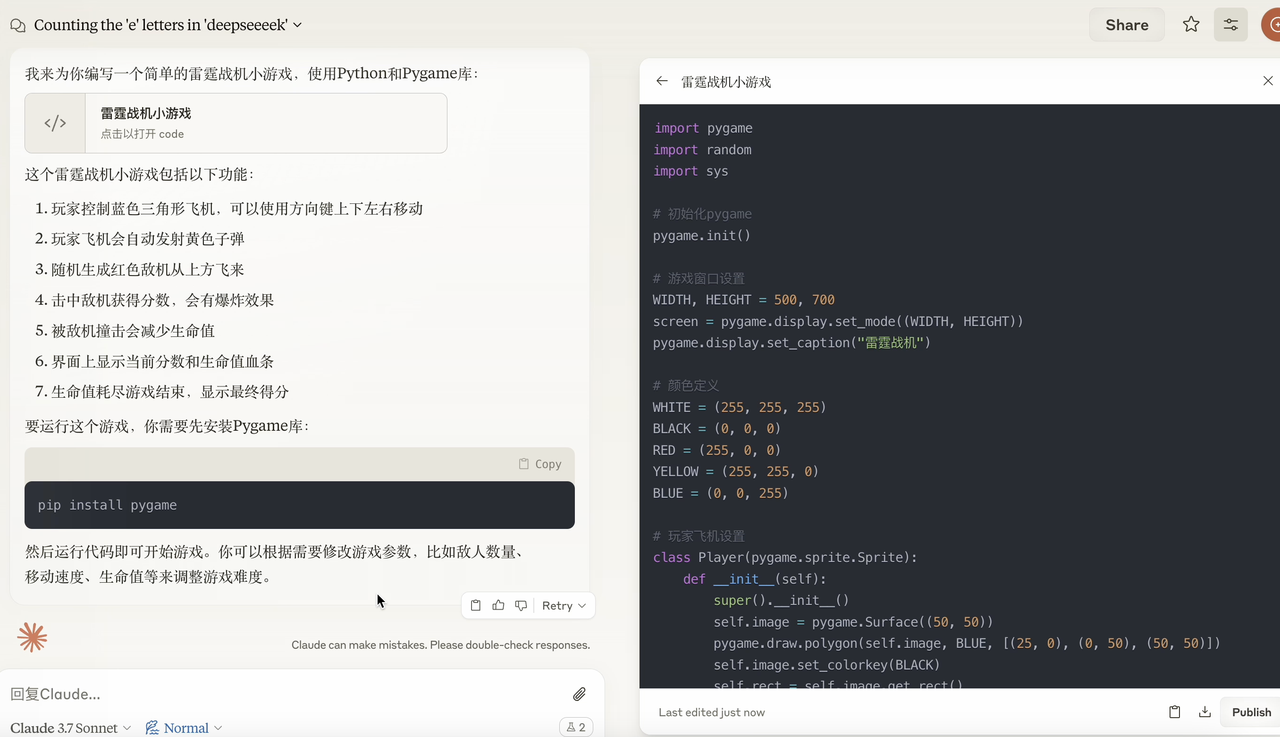
"Il faut une heure pour brûler une corde inégale. Comment l'utiliser pour juger une demi-heure ? Il faut au total une heure pour brûler une corde inégale du début à la fin. Maintenant, il y a plusieurs cordes du même matériau. Comment puis-je utiliser la méthode de combustion d'une corde pour chronométrer une heure et quinze minutes ?"
Une simple question de raisonnement a failli griller le CPU du Claude 3.7 Sonnet.
Je pense que vous avez remarqué que par rapport au processus de réflexion affiché par DeepSeek R1, le processus de réflexion divulgué par Claude 3.7 Sonnet est plus objectif et manque d'expression personnalisée. Il s'agit d'une conception intentionnelle.
Au lieu d'une formation standard du personnage sur le processus de réflexion du modèle, Anthropic a voulu donner à Claude une liberté maximale pour penser par lui-même, ce qui, comme l'esprit humain, peut contenir des idées qui ne sont pas tout à fait correctes ou encore matures.
De plus, Anthropic estime que le processus de réflexion affiché par le modèle ne reflète pas nécessairement fidèlement sa logique de prise de décision interne. Par conséquent, Anthropic réfléchit à l'opportunité de continuer à divulguer le processus de réflexion de Claude dans les versions futures et évalue ses avantages et ses inconvénients en fonction des commentaires des utilisateurs et des progrès de la recherche à l'avenir.
Fait intéressant, nous avons mentionné précédemment qu'à mesure que de nouveaux modèles sont publiés les uns après les autres, les différents numéros de version et règles de dénomination sont également éblouissants.
L'année dernière, lorsque Sam Altman, PDG d'OpenAI, a été interrogé sur la stratégie de dénomination des produits de l'entreprise, il a également admis que c'était un vrai casse-tête.
Le PDG d'Anthropic, Amodei, a également déclaré que même si la méthode de dénomination de Claude semblait bonne au début, avec l'itération et la mise à jour rapides du modèle, le système de dénomination encore utilisé est également devenu étendu.
Il a souligné qu’à l’heure actuelle, aucune entreprise d’IA n’a véritablement « résolu le problème de la dénomination » et que tout le monde travaille dur pour trouver des méthodes de dénomination plus simples et plus claires. Il s’agit peut-être également d’un rare consensus parmi les géants de l’IA.
Mike Krieger, directeur produit d'Anthropic, a également annoncé le nommage en coulisses de Claude 3.7 Sonnet sur la plateforme X.
Le processus de lutte intérieure est probablement comme ça

# Bienvenue pour suivre le compte public officiel WeChat d'Aifaner : Aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo