
Faire une vidéo avec ta bouche c’est vraiment à venir ! Cette nouvelle application, Meta, est terrifiante
Cette année est une année de grands progrès pour l'IA dans le domaine de la production d'images et de vidéos.
Quelqu'un a remporté le prix de l'art numérique avec une image générée par l'IA et a vaincu un groupe d'artistes humains ; il existe des applications telles que Tiktok qui génèrent des images par saisie de texte et les transforment en fond d'écran vert de courtes vidéos ; il existe de nouveaux produits qui peuvent faire du texte Générez une vidéo directement et réalisez directement l'effet de "créer une vidéo avec votre bouche".
Le produit vient cette fois de Meta, qui cultive profondément l'intelligence artificielle depuis de nombreuses années, et a été follement ridiculisé à cause du métaverse il y a quelque temps.

▲ Le Meta Metaverse a été sauvagement ridiculisé
Seulement cette fois, vous ne pouvez pas vous moquer de lui, car il a vraiment une petite percée.
Du texte à la vidéo, que peut-on faire
Maintenant, vous pouvez bouger votre bouche pour faire une vidéo.
Bien que ce soit un peu exagéré, Make-A-Video de Meta cette fois-ci se dirige probablement vraiment vers cet objectif.

Ce que Make-A-Video peut actuellement faire est :
- Text-to-video – transformez votre imagination en vidéos réelles et uniques
- Convertissez des images directement en vidéo – laissez une ou deux images se déplacer naturellement
- Vidéo Génération de vidéo étendue – Entrez une vidéo pour créer une variante vidéo
En termes de génération directe de vidéo à partir de texte, Make-A-Video a battu de nombreux étudiants professionnels en conception d'animation. Au moins, il peut faire n'importe quel style, et le coût de production est très faible.
Bien que le site Web officiel ne vous permette pas de générer directement une expérience vidéo, vous pouvez d'abord soumettre vos informations personnelles, puis Make-A-Video partagera tout développement avec vous en premier.

Il n'y a pas beaucoup de cas qui peuvent être vus jusqu'à présent, et les cas affichés sur le site officiel ont encore des endroits étranges dans les détails. Mais quoi qu'il en soit, le fait que le texte puisse être directement transformé en vidéo est une amélioration en soi.
Un ours en peluche dessine un autoportrait, et vous pouvez voir la projection artificielle de la main de l'ours sur la partie ombragée du papier.

Des robots dansent à Times Square.

Le chat tient la télécommande du téléviseur pour changer de chaîne. Les griffes du chat ressemblent beaucoup à des mains humaines, et parfois cela fait un peu peur à regarder.

Et un paresseux poilu dans un bonnet tricoté orange tripote un ordinateur portable, la lumière de l'écran d'ordinateur dans ses yeux.

Les styles ci-dessus sont surréalistes et les étuis qui ressemblent davantage à la réalité sont plus faciles à porter.
Les cas présentés par Make-A-Video sont bons s'ils ne se concentrent que sur des zones locales, comme le gros plan de l'artiste peignant sur la toile, le cheval buvant de l'eau et les petits poissons nageant dans le récif corallien.



Mais un jeune couple un peu plus réaliste marchant sous une pluie battante, c'est très bizarre, le haut du corps va bien, mais les pieds du bas du corps tremblent, parfois étirés, comme dans un film de fantômes.

Il existe également des vidéos de style peinture de vaisseaux spatiaux atterrissant sur Mars, de couples en smoking piégés par des averses, de la lumière du soleil sur des tables et de poupées panda en mouvement. En termes de détails, ces vidéos ne sont pas parfaites, mais grâce à l'effet innovant de l'IA text-to-video, elles sont toujours incroyables.




Les peintures statiques peuvent également être animées à l'aide de Make-A-Video – le bateau se déplace dans les grosses vagues.

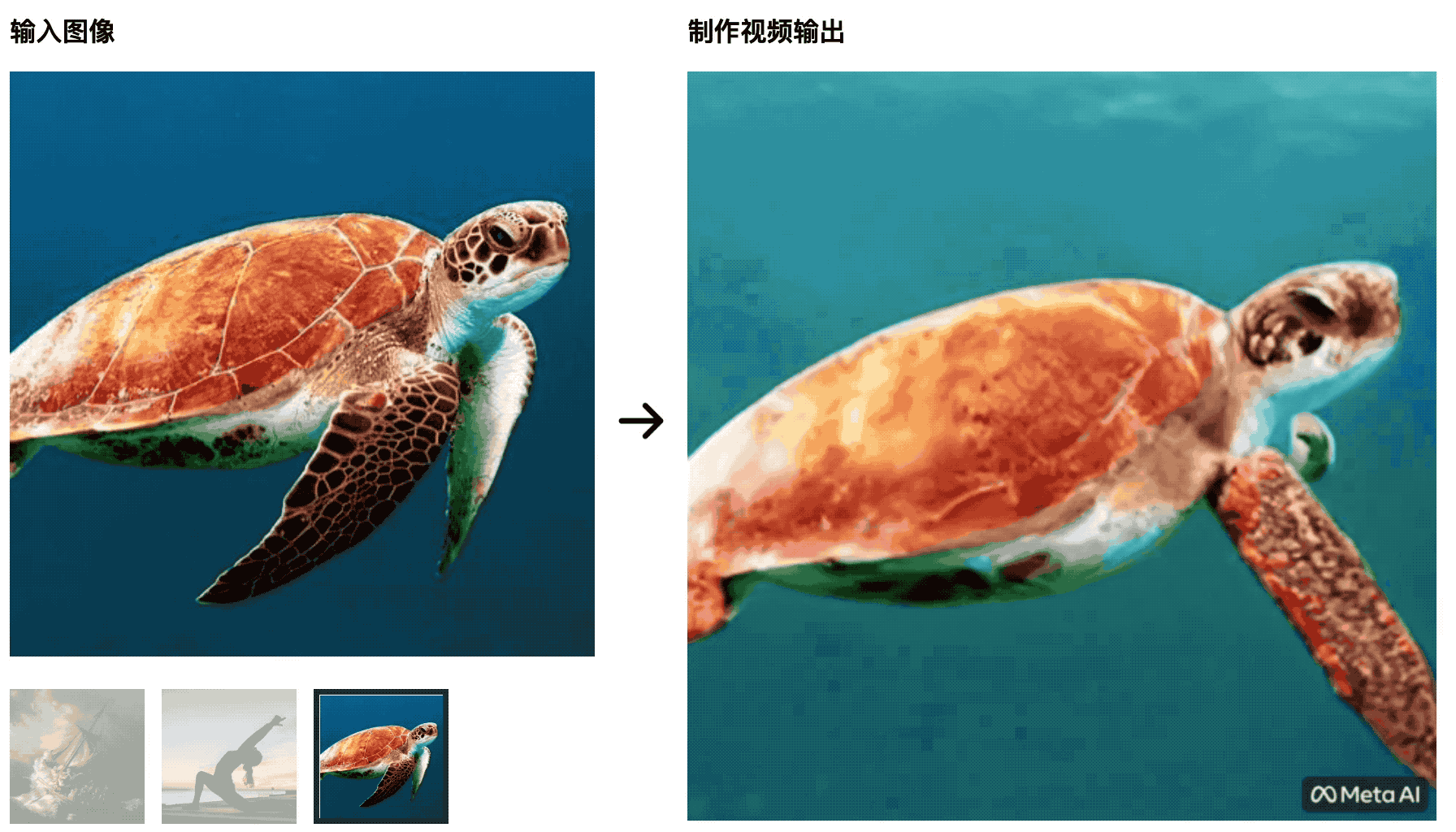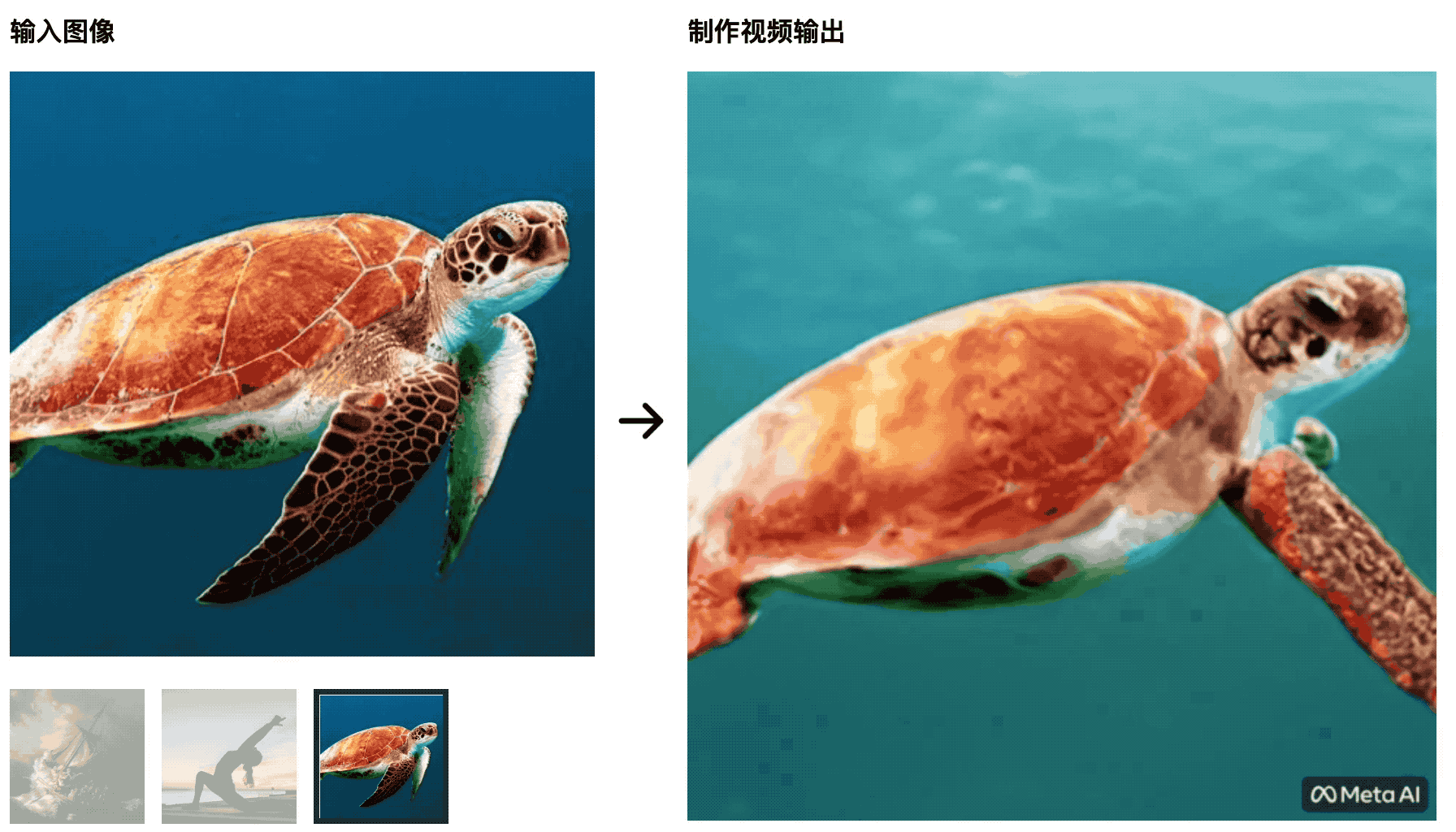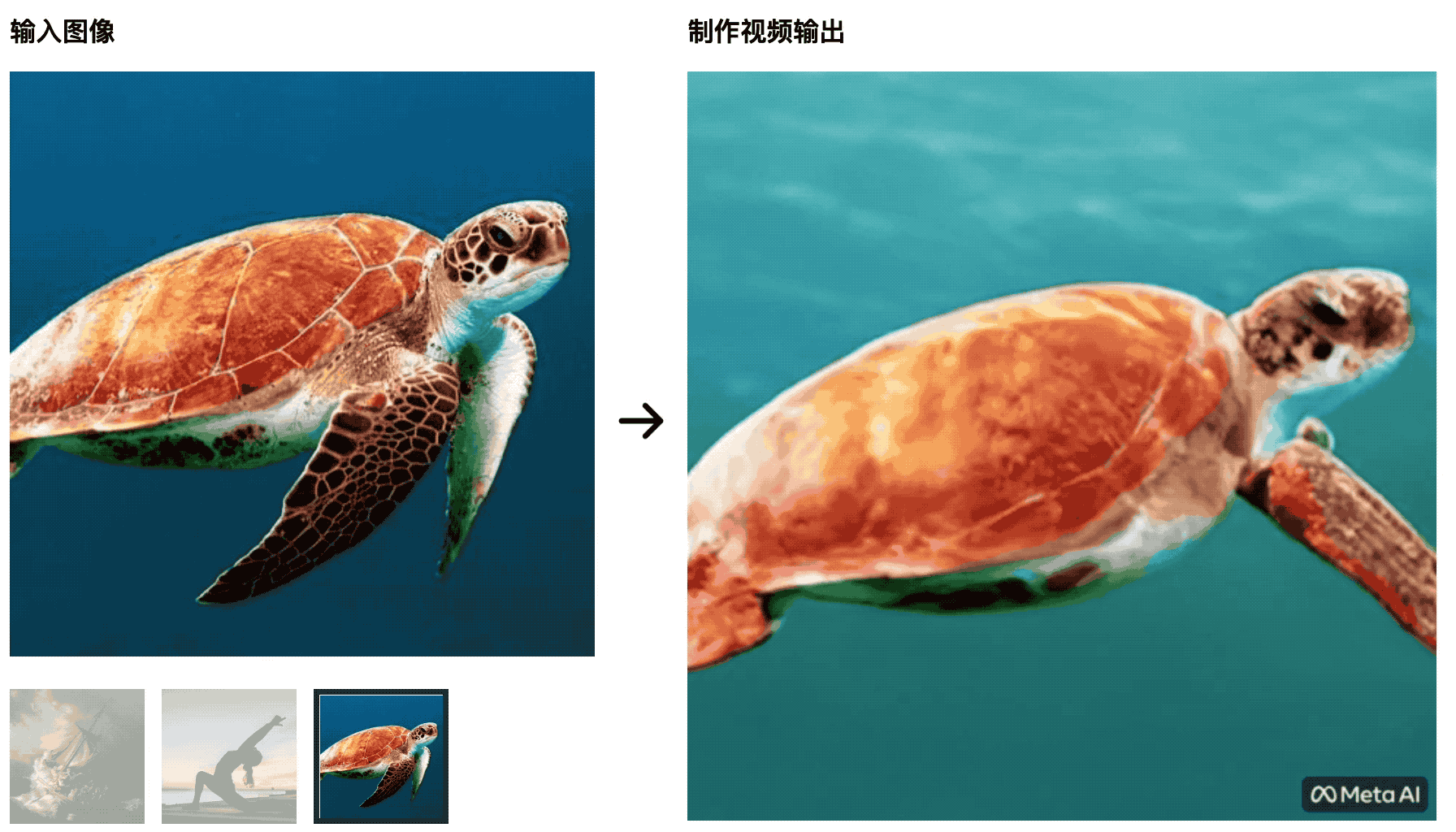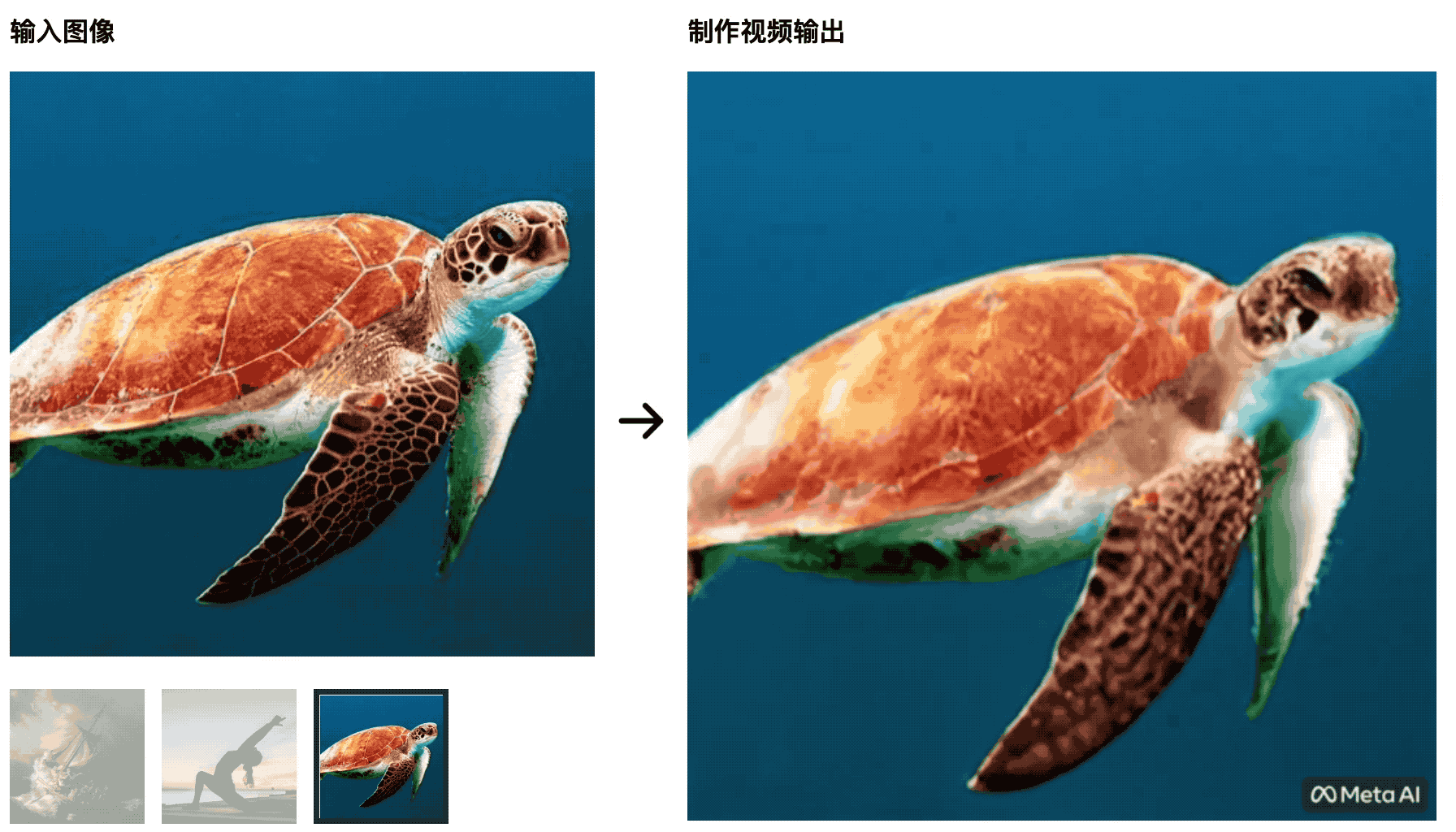
Les tortues nagent dans la mer. L'image initiale est très naturelle, mais plus tard, elle ressemble plus à une découpe d'écran vert, ce qui n'est pas naturel.
L'entraîneur de yoga étire son corps au soleil levant, et le tapis de yoga changera avec les changements de la vidéo – cette IA ne pourra pas vaincre les étudiants qui étudient la production cinématographique et télévisuelle, et les variables de contrôle ne sont pas bien faites.

Saisissez enfin une vidéo pour imiter son style afin de créer des variantes vidéo Il existe également 3 cas.
L'un des changements est relativement moins raffiné. La vidéo des astronautes flottant dans l'espace a été transformée en une version légèrement moins esthétique de 4 versions brutes de la vidéo.

Il y a pas mal de changements surprenants dans la vidéo du petit ours qui danse, du moins la posture de danse a changé.

Quant à la dernière vidéo du lapin mangeant de l'herbe, c'est la plus "anneng me distingue en tant que mâle et femelle". Il est difficile de reconnaître qui est la première vidéo dans les 5 dernières vidéos, et elle a l'air très harmonieuse.

Dès que le texte en images a progressé, la vidéo est là
Dans " Après AlphaGo, il subvertit à nouveau complètement la cognition humaine ", nous avons présenté une fois l'application de génération d'images DALL·E. Quelqu'un l'a utilisé pour créer des images pour rivaliser avec des artistes humains et finalement gagner.
Le Make-A-Video que nous voyons maintenant peut être considéré comme une version vidéo de DALL·E (version principale) – c'est comme le DALL·E il y a 18 mois, avec une énorme percée, mais l'effet actuel peut ne pas faire le les gens sont satisfaits.

▲ Peinture étendue créée par DALL·E
On peut même dire qu'il s'agit d'un produit qui repose sur les épaules du géant DALL·E et réalise des réalisations. Par rapport aux images générées par du texte, Make-A-Video n'a pas apporté trop de nouveaux changements dans le backend.
"Nous avons vu que les modèles décrivant des images générées par du texte étaient également étonnamment efficaces pour générer de courtes vidéos", ont déclaré les chercheurs dans leur article.

▲Œuvres primées décrivant des images générées par du texte
A l'heure actuelle, les vidéos produites par Make-A-Video présentent 3 avantages :
- Formation accélérée des modèles T2V (text to video)
- Pas besoin de données texte-vidéo couplées
- La vidéo convertie hérite du style de l'image/vidéo d'origine
Ces images ont certainement des inconvénients, et le manque de naturel susmentionné est bien réel. Et ils ne sont pas comme les vidéos nées à cette époque, la qualité de l'image est floue, le mouvement est rigide, la correspondance du son n'est pas prise en charge, la durée d'une vidéo ne dépasse pas 5 secondes et la résolution est de 64 x 64 pixels.

▲ Cette vidéo contient quelques images de la langue et des mains du chien qui sont très étranges
Le premier modèle CogVideo capable de synthétiser directement la vidéo à partir de texte, publié il y a quelques mois par une équipe de recherche de l'Université Tsinghua et de l'Institut de recherche Zhiyuan (BAAI), a également un tel problème. Basé sur l'architecture Transformer pré-entraînée à grande échelle, il propose une stratégie d'entraînement hiérarchique à fréquence d'images multiples, qui peut aligner efficacement le texte et les clips vidéo, mais qui ne résiste pas à l'examen.
Mais qui peut dire que 18 mois plus tard, Make-A-Video et CogVideo ne feront pas de meilleures vidéos que la plupart ?

▲ Vidéo générée par CogVideo – elle ne prend actuellement en charge que la génération chinoise
Bien qu'il n'y ait pas beaucoup d'outils de conversion de texte en vidéo qui ont été publiés, il y en a beaucoup sur la route. Après la sortie de Make-A-Video, les développeurs de la start-up StabilityAI ont déclaré publiquement : "Notre (application de synthèse vidéo) sera plus rapide et meilleure, et applicable à davantage de personnes."
La concurrence est meilleure, et la fonction texte-image de plus en plus réaliste en est la meilleure preuve.
#Bienvenue pour prêter attention au compte WeChat officiel d'Aifaner : Aifaner (WeChat : ifanr), un contenu plus excitant vous sera apporté dès que possible.
Love Faner | Lien d'origine · Voir les commentaires · Sina Weibo