
Interview de 10 000 mots de Fei-Fei Li : L’intelligence spatiale est la prochaine frontière de l’IA
Dans le monde de l'IA, les grands modèles de langage ont déjà impressionné. Mais Fei-Fei Li affirme que la véritable avancée reste à venir. Elle est convaincue que si l'IA ne peut pas comprendre le monde tridimensionnel, elle n'est pas complète. C'est son prochain objectif fou.
Il y a deux jours, Y Combinator a mis à jour sa chaîne YouTube avec une interview vidéo de Fei-Fei Li à l'AI Startup School de San Francisco. Dans cette conversation, Fei-Fei Li a évoqué la création du projet ImageNet, le développement rapide de l'apprentissage profond, de la reconnaissance d'objets aux modèles génératifs actuels, et a mis en lumière l'un des défis les plus complexes de l'intelligence artificielle sur lequel elle travaille actuellement : l'intelligence spatiale.
Fei-Fei Li est actuellement fondatrice et PDG de World Labs, une entreprise d'intelligence spatiale dédiée à la création de modèles du monde à grande échelle pour percevoir, générer et interagir avec le monde 3D. Lors de cette conversation, elle a également abordé une série de questions sur l' importance de la modélisation du monde 3D pour l'intelligence artificielle générale (IAG) et sur les raisons pour lesquelles l'intelligence spatiale peut être plus difficile à atteindre que le langage .
Enregistrer le débit pour voir la version :
Il s’agit d’un changement de paradigme dans l’apprentissage automatique
La naissance d'ImageNet n'est pas seulement le rêve personnel de Fei-Fei Li, mais aussi un changement de paradigme dans le domaine de la vision par ordinateur et de l'apprentissage profond. Elle a confié qu'à l'époque, elle était obsédée par l'idée de « permettre aux machines de voir », et que sa persévérance et son travail acharné ont créé un moment crucial où les données, les GPU et les réseaux neuronaux se sont réunis . Aujourd'hui, elle nourrit une nouvelle passion et entend bien continuer à mener une nouvelle révolution de l'IA.
Nous voulons faire de l'intelligence spatiale le nouveau champ de bataille de l'IA
De la reconnaissance d'objets à la compréhension de scènes, l'IA a progressivement commencé à comprendre des informations visuelles complexes. Une nouvelle vague de transformation s'est abattue sur l'ère actuelle de l'IAG. Elle est convaincue que le monde n'est pas purement génératif et que ce n'est qu'en permettant à l'IA de comprendre le monde tridimensionnel que nous pourrons véritablement évoluer vers l'IAG. L'acquisition de données pour les grands modèles linguistiques est simple, et les modèles d'intelligence spatiale constituent le prochain défi qu'elle devra relever.
Je ne peux pas révéler trop de détails sur World Labs.
Interrogée sur les scénarios d'application envisagés par World Labs et leurs différences avec l'architecture actuelle des LLM, Li Feifei a déclaré que l'intégration du logiciel et du matériel, ainsi que la réalisation du métavers, nécessiteront leur intelligence spatiale. Contrairement à la réalisation des LLM, elle a mentionné que les humains n'ont pas une perception précise du monde 3D, ce qui est très difficile. Cependant, elle croit en son équipe, composée des personnes les plus intelligentes au monde, et qu'avec eux, ils pourront résoudre ce problème dans le monde 2D.
Dans le domaine de l’IA, n’ayez jamais peur de l’échec
À la fin de l'entretien, Fei-Fei Li a partagé son expérience personnelle, de son immigration aux États-Unis pour y étudier, à sa nomination à la direction du Laboratoire d'intelligence artificielle de Stanford, en passant par la vice-présidence de Google, et enfin à la création de sa propre entreprise. Elle a expliqué qu'elle était toujours partie de zéro et avait travaillé dur . Elle a également encouragé les jeunes à suivre leurs centres d'intérêt et leur curiosité, à relever courageusement les défis et à résoudre des problèmes impossibles.

Vidéo originale : https://youtu.be/_PioN-CpOP0
Ce qui suit est la transcription de l'entretien, avec de légers ajustements dans la traduction
Le domaine de l’apprentissage automatique a besoin d’un changement de paradigme
Modératrice : Je suis ravie d’accueillir parmi nous le Dr Fei-Fei Li, qui a une longue carrière dans l’IA. Je pense que beaucoup la connaissent. Vous êtes également connue comme la « marraine de l’IA », et l’un de vos premiers projets a été Imagenet en 2009, il y a 16 ans. Ce projet, cité plus de 80 000 fois, a posé une pierre angulaire importante de l’IA : la problématique des données. Pouvez-vous nous expliquer comment ce projet a vu le jour ? Les travaux réalisés à l’époque étaient véritablement révolutionnaires.

Fei-Fei Li : Oui, tout d'abord, merci à Diana, Gary et à tous ceux qui sont ici de m'avoir invité. Je suis très heureux d'être ici, car je me sens comme tout le monde. Je suis aussi entrepreneur maintenant, je viens de créer une entreprise, donc je suis très heureux d'être ici.
Oui, vous avez raison, nous avons conçu ce projet il y a presque 18 ans, le temps passe si vite. J'étais en première année de maître de conférences à l'Université de Princeton. À cette époque, le monde de l'intelligence artificielle et de l'apprentissage automatique était radicalement différent de ce qu'il est aujourd'hui. Il y avait très peu de données, et, du moins dans le domaine de la vision par ordinateur, les algorithmes ne fonctionnaient pas du tout. L'industrie était encore inexistante à l'époque, et le grand public connaissait à peine le mot « intelligence artificielle ». Mais il existait encore un groupe de personnes, à commencer par les fondateurs de l'intelligence artificielle, comme John McCarthy, puis des gens comme Jeff Hinton. Je pense que nous rêvons tous d'intelligence artificielle, et nous voulons vraiment que les machines soient capables de penser et de travailler. Personnellement, je rêve de doter les machines de capacités visuelles, car la vision est la pierre angulaire de l'intelligence, et l'intelligence visuelle ne se résume pas à la perception, mais aussi à la compréhension du monde et à son fonctionnement.
J'étais donc très obsédé par le problème de « permettre aux machines de voir ». Dans mon obsession pour le développement d'algorithmes d'apprentissage automatique, nous avons essayé les réseaux de neurones, mais cela n'a pas fonctionné. Nous nous sommes tournés vers d'autres méthodes, comme les machines à vecteurs de support, mais un problème m'a toujours préoccupé : le problème de la généralisation. Si vous travaillez dans l'apprentissage automatique, vous devez comprendre que la généralisation est le fondement mathématique et l'objectif principal de l'apprentissage automatique. Pour que ces algorithmes puissent généraliser, les données sont cruciales, mais il n'y avait pratiquement pas de données dans le domaine de la vision par ordinateur à l'époque. Et il se trouve que j'ai fait partie de la première génération d'étudiants diplômés à commencer à travailler avec les données, car j'ai été la première génération d'étudiants diplômés à assister à l'émergence d'Internet et de l'Internet des objets.
Vers 2007, mes étudiants et moi avons décidé de franchir une étape décisive. Nous avons parié que le domaine de l'apprentissage automatique avait besoin d'un changement de paradigme, mené par des méthodes basées sur les données. Mais les données manquaient à l'époque. Nous avons donc décidé, faute de données, d'aller sur Internet et de télécharger des milliards d'images, soit le plus grand nombre disponible sur Internet, afin de créer un système mondial de classification visuelle pour entraîner et évaluer les algorithmes d'apprentissage automatique. C'est pour cette raison que le projet ImageNet a vu le jour et a été mis en œuvre.
Les données et l'open source ouvrent la voie au développement de l'apprentissage profond
Animateur : En effet, ce n’est qu’avec l’émergence d’algorithmes prometteurs que des avancées ont commencé à se produire. Ce n’est qu’avec la sortie d’AlexNet en 2012 que l’obtention d’une puissance de calcul suffisante et l’investissement de ressources suffisantes sont devenus le deuxième facteur clé sur la voie de l’IA. Ces algorithmes ont révélé un moment critique : lorsque l’IA est alimentée par des données, la communauté commence progressivement à trouver de nouvelles solutions, ce qui donne une impulsion au développement de l’IA.
Fei-Fei Li : En 2009, nous avons publié un petit article uniquement sous forme d'affiche CVPR.
De 2009 à 2012, jusqu’à l’avènement d’AlexNet, nous pensions vraiment que les données seraient le moteur de l’IA, mais nous n’avions pratiquement aucun signe clair que cette approche fonctionnerait.
Nous avons donc pris plusieurs mesures. Tout d'abord, nous avons décidé de le rendre open source. Dès le départ, nous avons pensé qu'il devait être open source pour que l'ensemble de la communauté scientifique puisse l'utiliser et collaborer à la résolution de ce problème.
Deuxièmement, nous avons créé un défi pour réunir les étudiants et chercheurs les plus brillants du monde entier et travailler sur ce problème. C'est ce que nous appelons le Défi ImageNet. Chaque année, nous publions un jeu de données de test. L'intégralité des données ImageNet de la plateforme est utilisée pour l'entraînement. Nous publions également un jeu de données de test distinct et invitons tout le monde à participer publiquement.
Les premières années ont véritablement servi à établir une référence. Le taux d'erreur de performance était d'environ 30 %, ce qui n'était pas une erreur nulle, ni complètement aléatoire, mais pas exceptionnel. Mais dès la troisième année, en 2012, j'ai également relaté cette expérience dans mon livre publié.
▲ La première place du ImageNet Challenge est occupée par SuperVision
Je me souviens encore, c'était la fin de l'été, et nous étions en train d'exécuter tous les résultats du défi ImageNet sur nos serveurs. Tard dans la nuit, j'ai reçu un message de mon étudiant en master m'informant qu'un résultat était vraiment remarquable et que nous devrions le vérifier. Nous avons fait des recherches et découvert qu'il s'agissait d'un réseau de neurones convolutifs. Ce n'était pas AlexNet à l'époque, mais un travail de l'équipe de Geoffrey Hinton appelé « SuperVision ». C'était un jeu de mots très astucieux, combinant « super » et « apprentissage supervisé ». Nous avons examiné les travaux de SuperVision, qui est en fait un vieil algorithme. Les réseaux de neurones convolutifs avaient été publiés dès les années 1980, mais ils avaient simplement apporté quelques ajustements à l'algorithme. Cependant, lorsque nous l'avons découvert pour la première fois, nous avons été vraiment surpris par cette avancée majeure.
Bien sûr, la première chose que vous savez, c'est que nous avons présenté ce projet lors de l'atelier ImageNet Challenge à Florence, à l'ICCV (Conférence internationale sur la vision par ordinateur), cette année-là. Alex Krizhevsky et son équipe étaient présents, et de nombreuses personnes étaient présentes. Aujourd'hui, tout le monde appelle ce moment « AlexNet moment » de l'ImageNet Challenge.
J'aimerais également ajouter que ce n'était pas seulement le succès du réseau de neurones convolutifs, mais aussi la première fois qu'Alex et son équipe combinaient deux GPU pour des calculs d'apprentissage profond. Ce fut véritablement le premier événement majeur de la combinaison de données, de GPU et de réseaux de neurones.
Ma carrière ne consiste pas seulement à raconter des scènes
Modérateur : Suivant la tendance de développement de l’intelligence artificielle, ImageNet a posé les bases de la résolution du problème de la reconnaissance d’objets. L’intelligence artificielle a ainsi atteint le stade où elle peut résoudre le problème de la compréhension de scènes. Vous et vos étudiants, comme André Karpathy, commencez à décrire des scènes. Pouvez-vous nous parler de la transition de la reconnaissance d’objets à la compréhension de scènes ?
Fei-Fei Li : Oui, ImageNet résout le problème de l'identification visuelle d'objets dans une image, comme « ceci est un chat, ceci est une chaise », un problème fondamental de la reconnaissance visuelle. Mais depuis que j'ai commencé à m'intéresser à l'intelligence artificielle en tant qu'étudiant diplômé, j'ai un rêve. Je pense que ce rêve pourrait prendre cent ans à se réaliser : raconter l'histoire du monde. Imaginez qu'en ouvrant les yeux, on ne voie pas « personnes, chaises, tables », mais une salle de conférence, un écran, une scène, un public, une caméra, etc. On peut décrire une scène dans son intégralité, ce qui est une capacité humaine, la base de l'intelligence visuelle, et c'est essentiel à notre quotidien. C'est pourquoi j'ai toujours pensé que ce problème occuperait toute ma vie. Après avoir obtenu mon diplôme, je me suis dit que si je parvenais à créer un algorithme capable de raconter l'histoire d'une scène, alors je réussirais. C'était ma vision de ma carrière à l'époque.
Cependant, ce moment est vraiment arrivé avec l’essor de l’apprentissage profond, puis André et Justin Johnson ont rejoint mon laboratoire, et nous avons commencé à voir des signes de collision entre le langage naturel et la vision.
André et moi avons abordé le problème de la description d'images, ou narration. En résumé, vers 2015, nous avons publié une série d'articles, dont certains en même temps que nous, qui comptaient parmi les premiers travaux sur la capacité des ordinateurs à générer des légendes d'images. Je me suis presque demandé : « Comment vais-je aller de l'avant ? » C'était le rêve de ma vie. Ce fut un moment très fort pour nous deux.

L'année dernière, j'ai donné une conférence TED et j'ai utilisé un tweet qu'André avait envoyé quelques années auparavant, juste après avoir terminé ses travaux sur les légendes d'images. C'était en quelque sorte sa thèse de doctorat. Je lui ai dit en plaisantant : « Hé, André, pourquoi ne pas faire l'inverse ? Générer une image à partir d'une phrase . » Bien sûr, il savait que je plaisantais et il a répondu : « Haha, je pars en premier. » Le monde n'était clairement pas prêt pour ça. Mais aujourd'hui, nous savons tous que l'IA générative peut désormais générer de belles images à partir d'une phrase. La morale de l'histoire, c'est que l'IA a connu une évolution considérable.
Personnellement, je me sens très chanceux, car toute ma carrière a débuté à la fin de l'hiver de l'IA et au début de son essor. Une grande partie de mon travail et de ma carrière sont étroitement liés à ce changement, ou l'ont d'une manière ou d'une autre favorisé. Je me sens donc très chanceux, reconnaissant et, d'une certaine manière, fier.
Animateur : Je pense que le plus fou, c’est que même si vous avez réalisé votre rêve de décrire des scènes, et même de les générer grâce à des modèles de diffusion, vous continuez à voir plus grand. Car toute la trajectoire de la vision par ordinateur est passée de la reconnaissance d’objets à la compréhension de scènes, et maintenant au concept de « monde ». Et vous avez décidé de quitter le monde universitaire, d’un poste de professeur, pour l’entrepreneuriat, en devenant le fondateur et PDG de World Labs. Pouvez-vous nous parler de ce qu’est le « monde » ? Est-ce plus complexe que les scènes et les objets ?
Fei-Fei Li : Oui, c’est vraiment incroyable. Bien sûr, tout le monde sait ce qui s’est passé par le passé, et pour moi, il est vraiment difficile de résumer les progrès des cinq ou six dernières années. Nous vivons une époque de progrès technologique. En tant que scientifique en vision par ordinateur, nous avons assisté à une croissance incroyable, des images aux descriptions d’images, en passant par la génération d’images grâce aux techniques de diffusion. Si ces avancées sont passionnantes, nous voyons également un autre domaine extrêmement prometteur : le langage, et notamment les LLM (grands modèles de langage). Par exemple, en novembre 2022, l’émergence de ChatGPT a véritablement ouvert la voie aux modèles génératifs, capables de passer le test de Turing, etc. Du coup, même les plus anciens comme moi sont très enthousiastes et commencent à réfléchir avec audace à la prochaine étape.

En tant que scientifique en vision par ordinateur, je suis souvent inspiré par l'évolution et la neuroscience. Au cours de ma carrière, je suis souvent à la recherche du prochain problème « étoile polaire » à résoudre. Je me suis souvent demandé : qu'est-ce que l'évolution ou le développement du cerveau a fait ? Il est remarquable et appréciable que l'évolution du langage humain ait pris entre 300 et 500 millions d'années. Même si nous sommes très généreux, cela ne représente que moins d'un million d'années. Les humains sont la seule espèce à posséder un langage complexe. On peut parler du langage animal, mais en termes de fonction du langage comme outil de communication, de raisonnement et d'abstraction, seuls les humains possèdent cette capacité. Ce processus évolutif a duré moins de 500 000 ans.
Mais si vous pensez à la vision, pensez à la capacité de comprendre le monde tridimensionnel, de comprendre comment se déplacer dans ce monde tridimensionnel, comment naviguer, interagir, comprendre, communiquer avec lui, tout cela a pris 540 millions d’années à évoluer.
Il y a environ 540 millions d'années, les premiers trilobites ont commencé à développer une perception visuelle sous l'eau. Depuis, la vision est devenue la clé de la course aux armements évolutionnaires. Avant l'apparition de la vision, les formes de vie animale étaient relativement simples, sans pratiquement aucune évolution complexe pendant près de 500 millions d'années. Mais au cours des 540 millions d'années suivantes, c'est précisément grâce à la capacité à comprendre le monde que la course aux armements évolutionnaires a commencé et que l'intelligence des animaux a continué de progresser.

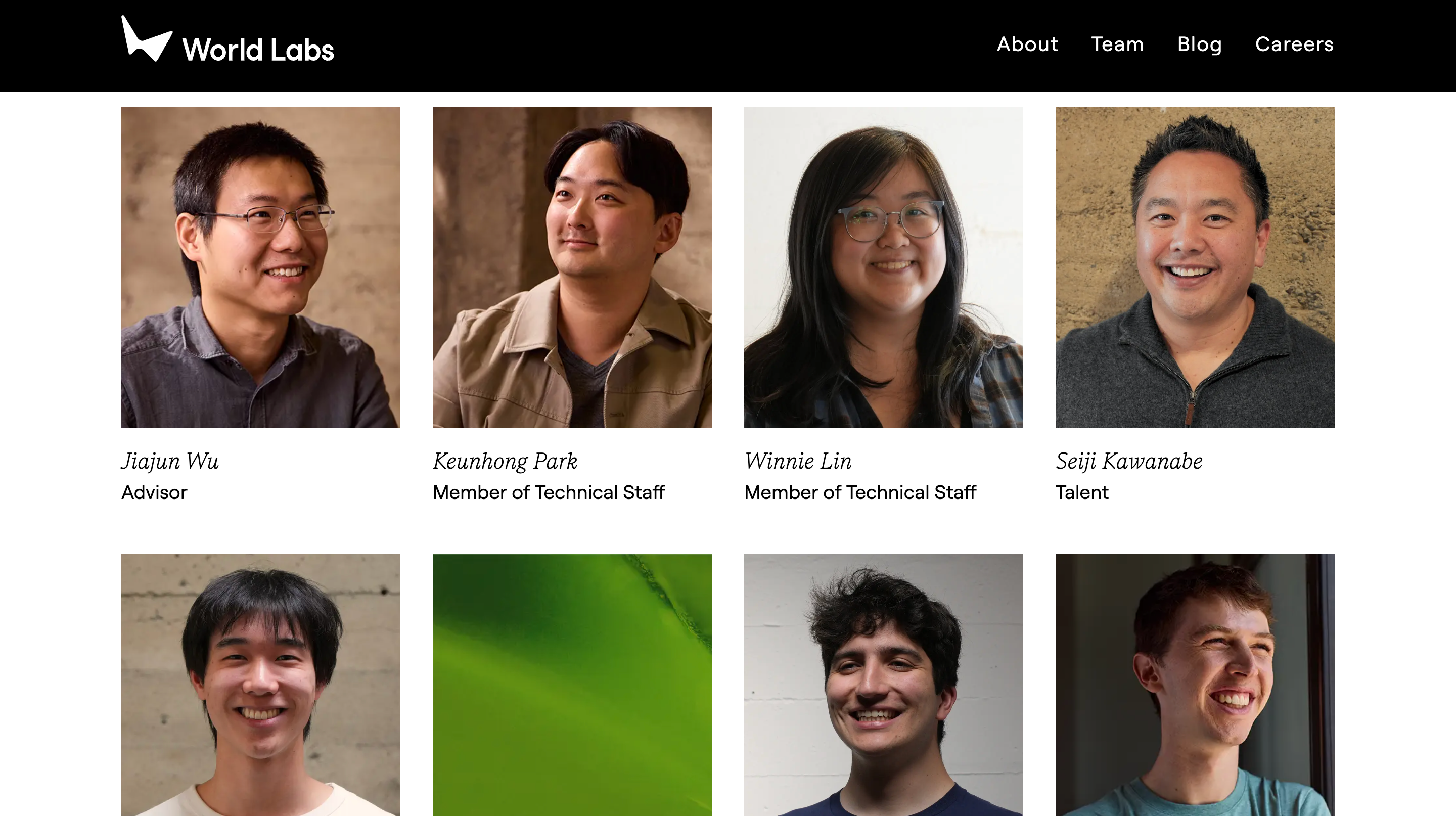
▲ L'équipe fondatrice d'iWorld Labs, Fei-Fei Li (première à partir de la droite), Justin Johnson, Christoph Lassner, Ben Mildenhall
Pour moi, résoudre le problème de l'intelligence spatiale, comprendre le monde 3D, le générer, raisonner sur ce monde, réaliser des choses dans ce monde, est un enjeu fondamental pour l'IA. Pour moi, l'IA générale est incomplète sans intelligence spatiale. Je veux résoudre ce problème. Et cela implique de créer des « modèles du monde » qui vont au-delà des pixels plats, au-delà du langage, pour capturer véritablement la structure 3D et l'intelligence spatiale du monde. Heureusement, quel que soit mon âge, je travaille toujours avec des jeunes talents exceptionnels. Je lance donc cette entreprise avec trois jeunes technologues exceptionnels, mais de renommée mondiale : Justin Johnson, Ben Mildenhall et Christoph Lassner. Nous allons tenter de résoudre ce que je considère comme le problème le plus complexe de l'IA à l'heure actuelle.
Il est beaucoup plus difficile d’obtenir des données sur l’intelligence spatiale que sur le langage.
Animateur : En effet, ce sont tous des gens très talentueux. Chris est le fondateur de Pulsar, une technologie de rendu différentiable et désormais un backend de rendu sphérique pour PyTorch3D. Et Justin Johnson, un de vos anciens étudiants, possède une solide expertise en ingénierie système et a mis en œuvre un transfert de style en temps réel basé sur des réseaux de neurones. Enfin, Ben est l'auteur de l'article NeRF (Neural Radiance Fields). Il s'agit donc d'une équipe d'élite. Une équipe d'élite est indispensable, car nous en avons déjà parlé : la vision est plus complexe que le langage. C'est peut-être un peu controversé, car les masters de maîtrise sont essentiellement unidimensionnels, mais vous parlez de la compréhension de nombreuses structures 3D. Alors pourquoi est-ce si difficile ? Pourquoi est-ce plus puissant que les grands langages actuels ?
Fei-Fei Li : Oui, vous comprenez la difficulté de notre problème. Le langage est intrinsèquement unidimensionnel, et la grammaire émerge par séquence, ce qui explique pourquoi la modélisation séquence à séquence est si classique. Un autre point important est que le langage est un signal purement génératif, ce que beaucoup ignorent. Il n'existe pas de langage dans la nature, on ne peut le toucher, on ne peut le voir, il est entièrement généré par l'esprit de chacun. Le langage est un signal purement génératif. Bien sûr, lorsqu'on l'écrit sur papier, il est là, mais la génération, la construction et l'utilité du langage sont intrinsèquement très génératives, et le monde est bien plus complexe que cela.
Tout d'abord, le monde réel est tridimensionnel. Si l'on ajoute le temps, il devient quadridimensionnel, mais nous ne considérerons pour l'instant que l'espace. Le monde réel est essentiellement tridimensionnel, ce qui constitue en soi un problème combinatoire plus complexe.
Deuxièmement, il faut comprendre combien il est difficile de percevoir le monde visuel comme un processus de projection, qu'il s'agisse de nos yeux, de notre rétine ou d'un appareil photo, qui compresse systématiquement l'information tridimensionnelle en deux dimensions. Mathématiquement, il s'agit d'un processus irréversible, c'est pourquoi les humains et les animaux disposent de multiples sens pour résoudre ce problème.
Troisièmement, le monde n'est pas purement génératif. Certes, nous pouvons générer un monde virtuel en 3D, mais il doit néanmoins respecter les lois de la physique, et le monde réel existe en dehors de nous. On passe désormais de manière fluide de la génération à la reconstruction. Le comportement de l'utilisateur, la praticité et les scénarios d'application sont radicalement différents. Si l'on se concentre sur la générosité, on peut parler de jeux, de métavers, etc. ; si l'on se concentre sur le monde réel, on parle de robotique, etc. Mais tout cela s'inscrit dans le continuum de la modélisation du monde et de l'intelligence spatiale.
Bien sûr, le grand défi actuel réside dans la quantité de données linguistiques disponibles sur Internet, et les données sur l'intelligence spatiale, bien que toutes présentes dans notre cerveau, ne sont pas aussi facilement accessibles que les données linguistiques. Voilà donc pourquoi ce problème est si complexe. Mais franchement, c'est ce qui me passionne, car si ce problème était simple, cela voudrait dire que quelqu'un d'autre l'aurait résolu. Et toute ma carrière a été consacrée à résoudre des problèmes extrêmement difficiles, presque illusoires. Je pense que c'est ce problème illusoire. Merci de votre soutien sur ce problème.
Nos laboratoires mondiaux comptent les personnes les plus intelligentes du monde
Animateur : Oui, même en partant des principes les plus élémentaires, le cortex visuel du cerveau humain possède bien plus de neurones traitant les données visuelles que ceux traitant le langage. Comment cette différence se manifeste-t-elle dans les modèles ? Par ailleurs, vos travaux en architecture seront très différents de ceux du LLM, n'est-ce pas ?
Fei-Fei Li : C'est une excellente question. En fait, il existe actuellement deux approches différentes pour y répondre.
L'une d'elles est l'approche LLM, où de nombreux modèles d'écriture et d'extension d'écriture observés dans les LLM peuvent être quasiment directement développés grâce à l'apprentissage auto-supervisé jusqu'à ce qu'une « fin heureuse » soit atteinte. On peut presque forcer l'auto-supervision jusqu'à atteindre son objectif.
L'autre consiste à construire un modèle du monde, qui peut être plus détaillé et hiérarchisé, car le monde est structuré et nous pouvons avoir besoin de signaux pour le guider. On peut le considérer comme une connaissance préalable, ou comme un signal de supervision dans les données ; c'est un moyen de guider l'apprentissage.
Je pense que ce sont là quelques-unes des questions ouvertes qu'il nous faut résoudre, mais vous avez raison. Si l'on considère la perception humaine, tout d'abord, nous n'avons même pas encore complètement résolu tous les problèmes de la vision humaine, n'est-ce pas ? Quel est le rôle de la 3D dans la vision humaine ? Ce n'est toujours pas un problème résolu. Nous savons que mécaniquement, les yeux ont besoin d'informations par triangulation, mais malgré cela, nous manquons d'un modèle mathématique parfait, et en réalité, les humains ne sont pas particulièrement doués pour la perception 3D. Nous ne sommes pas très doués pour comprendre et manipuler le monde tridimensionnel, ce qui laisse beaucoup de questions sans réponse.
▲ Captures d'écran de certains membres de World Labs
Nous sommes donc vraiment dans la phase des « Labos Mondiaux ». La seule chose sur laquelle je peux compter, c'est que je suis convaincu que nous disposons des personnes les plus intelligentes au monde pour résoudre ce problème dans le « Monde du Pixel ».
La convergence du matériel et des logiciels finira par arriver
Modérateur : Peut-on dire que le résultat final de ces modèles de base construits par World Labs est un monde en 3D ? Quels scénarios d’application envisagez-vous ? J’ai vu que vous avez évoqué diverses possibilités, de la perception à la génération. Il existe toujours une tension entre les modèles génératifs et les modèles discriminatifs. Quel est donc le rôle de ces mondes en 3D ?
Fei-Fei Li : Oui, je ne peux peut-être pas en dire plus sur les détails de World Labs, mais en matière d'intelligence spatiale, c'est un domaine qui me passionne. Tout comme le langage, les applications sont très variées. Dès le début de la création, les designers, les architectes, les designers industriels et même les artistes, les graphistes 3D et les développeurs de jeux peuvent l'utiliser. La robotique et l'apprentissage robotique constituent également un domaine d'application majeur, et les utilisations des modèles d'intelligence spatiale ou des modèles du monde sont très vastes. De plus, de nombreux secteurs connexes, comme le marketing, le divertissement et même le métavers, seront concernés. Je suis très enthousiaste à propos du métavers. Bien qu'il ne soit pas encore pleinement développé, je sais qu'il n'est pas encore très mature, mais c'est précisément pour cette raison que je suis encore plus enthousiaste. Je pense que l'intégration du matériel et du logiciel finira par se faire, et le potentiel futur est immense. C'est également une voie d'application très prometteuse.

Animateur : Je suis personnellement très heureux que vous résolviez le problème du métavers. J'ai déjà essayé cette voie dans mon entreprise, et je suis donc ravi de voir que vous vous y attaquez maintenant.
Li Feifei : Oui, je pense qu'il y a davantage de signes indiquant que le métavers se concrétise progressivement. Je pense que le matériel est effectivement un obstacle, mais plus important encore, il faut créer du contenu, et la création de contenu pour le métavers nécessite des modèles mondiaux.
Partir de zéro, c'est ma zone de confort
Modérateur : Changeons de sujet. Pour certains spectateurs, votre transition du monde universitaire au poste de fondateur et PDG peut paraître soudaine. Mais en réalité, votre parcours est tout à fait extraordinaire, et ce n’est pas la première fois que vous passez de zéro à un. Vous m’avez raconté comment vous avez immigré aux États-Unis, que vous ne parliez pas anglais au début et que vous avez dirigé une blanchisserie avec votre équipe pendant plusieurs années. Pouvez-vous nous parler de la façon dont ces expériences vous ont façonné aujourd’hui ?
Fei-Fei Li : N'est-ce pas ? Je sais que vous êtes là pour entendre mon histoire et comment j'ai ouvert une blanchisserie. Haha.
J'avais 19 ans et j'étais complètement désespéré. Je n'avais aucun moyen de subvenir aux besoins de ma famille, mes parents voulaient que j'aille à l'université et je voulais étudier la physique à Princeton. J'ai donc ouvert un pressing. Pour reprendre le jargon de la Silicon Valley, j'étais collecteur de fonds, fondateur et PDG, caissier et j'assurais toutes les tâches ménagères, et j'ai finalement « quitté » l'entreprise au bout de sept ans.
Pour revenir au point de Diana, surtout pour vous tous, je vous regarde et c'est vraiment excitant parce que vous êtes la moitié, voire un tiers, plus jeune que moi et vous êtes tellement talentueux, foncez, n'ayez pas peur.
J'ai été comme ça toute ma carrière, y compris, bien sûr, en travaillant à la blanchisserie, et même en tant que professeur, j'ai fait quelques choix. J'ai même choisi d'intégrer des départements qui n'avaient pas de professeur de vision par ordinateur, pour être le premier, ce qui était contraire à beaucoup de conseils. En tant que jeune professeur, tout le monde vous recommandera d'aller dans un endroit où il y a une communauté et un mentor senior. Bien sûr, j'espère aussi avoir un mentor senior, mais sinon, je suivrai mon propre chemin. Je n'ai donc aucune crainte. Plus tard, je suis allé chez Google et j'ai beaucoup appris sur le business, sur Google Cloud et le B2B, puis j'ai créé une startup à Stanford, car en 2018, l'IA n'est plus seulement un problème industriel, c'est devenu un problème humain.
L'humain sera toujours le moteur du progrès technologique, mais nous ne pouvons pas perdre notre humanité. Je suis très concentré sur la manière d'apporter une lueur d'espoir au progrès de l'IA, sur la manière dont l'IA peut être centrée sur l'humain et sur la manière dont l'IA peut aider les humains. Je suis donc retourné à Stanford et j'ai fondé un institut d'IA centré sur l'humain, que j'ai dirigé comme une startup pendant cinq ans. Certains ne seront peut-être pas ravis que j'aie dirigé cette startup aussi longtemps à l'université, mais j'en suis très fier. Donc, d'une certaine manière, j'aime être entrepreneur. J'aime la sensation de repartir de zéro, comme si on était à zéro, d'oublier ce qu'on a fait par le passé, d'oublier ce que les autres pensent de nous, et de se lancer. C'est ma zone de confort, et j'adore cette sensation.
Ce que je recherche, c’est l’intrépidité intellectuelle.
Animateur : C'est vraiment formidable que vous ayez accompli toutes ces choses extraordinaires et que vous ayez encadré de nombreux chercheurs légendaires, comme Andrej Karpathy, Jim Fan (aujourd'hui chez Nvidia) et Jia Deng (collaboration sur le projet ImageNet). Ils sont tous devenus des leaders du secteur. Lorsqu'ils étaient encore étudiants, qu'est-ce qui vous a fait entrevoir qu'ils accompliraient des choses extraordinaires à l'avenir ? Quels conseils pourriez-vous nous donner pour identifier ces personnes qui révolutionneront le domaine de l'IA ?
Fei-Fei Li : Tout d'abord, je me sens très chanceuse et je ne pense pas avoir apporté plus à mes étudiants qu'eux. Ils font vraiment de moi une meilleure personne, une meilleure enseignante et une meilleure chercheuse. C'est un véritable honneur pour moi de travailler avec autant d'étudiants légendaires, comme vous l'avez dit. Chaque étudiant est très différent. Certains sont de purs scientifiques qui se consacrent à la résolution de problèmes scientifiques ; d'autres sont des leaders du secteur ; et d'autres encore sont de grands diffuseurs de connaissances en IA. Mais je pense qu'ils ont tous un point commun, et j'encourage chaque étudiant ici présent à réfléchir à cette question.
C'est aussi le critère que je recherche chez les entrepreneurs, notamment lors du recrutement : l'audace intellectuelle.
Je pense que ce n'est pas seulement une question d'origine ou de problème à résoudre, mais aussi de courage pour relever le défi et s'engager à le relever. Cette audace est véritablement la qualité essentielle de la réussite. J'ai appris cela de ces étudiants et, en tant que PDG de notre laboratoire, j'y accorde une grande importance dans mon processus de recrutement.
Animateur : Vous recrutez également beaucoup de personnes pour World Labs, vous recherchez donc les mêmes postes ?
Fei-Fei Li : Oui, nous recrutons en masse. Nous recrutons des talents en ingénierie, en produits, en 3D et en modélisation générative. Si vous êtes audacieux et passionné par la résolution de problèmes complexes, n'hésitez pas à me contacter ou à consulter notre site web.
Questions et réponses du public
Questionneur 1 : Bonjour Feifei, merci pour votre exposé. Je suis un grand fan de vous ! Ma question est la suivante : vous avez travaillé sur la reconnaissance visuelle il y a plus de 20 ans. Je souhaite maintenant commencer un doctorat. Quelle orientation dois-je suivre pour devenir une légende comme vous ?
Fei-Fei Li : Je veux vous donner une réponse réfléchie car je peux toujours vous dire de faire ce qui vous passionne.
Tout d'abord, je pense que la recherche en IA a évolué, car si vous faites un doctorat, vous évoluez dans le monde universitaire. Aujourd'hui, le monde universitaire ne dispose plus de la plupart des ressources en IA, ce qui est très différent de ma situation. La puissance de calcul et les ressources en données y sont très limitées, tandis que l'industrie peut mener des recherches à un rythme beaucoup plus rapide. Par conséquent, en tant que doctorant, je vous recommande de rechercher des orientations qui n'entrent pas en conflit avec les problèmes que l'industrie peut résoudre grâce à une puissance de calcul accrue, des données plus riches et les avantages du travail en équipe. Il existe encore des problèmes fondamentaux que le monde universitaire peut continuer d'explorer, et même avec plus de puces, de grands progrès peuvent être réalisés.
Tout d'abord, l'IA interdisciplinaire est un domaine très stimulant pour moi dans le monde universitaire, notamment en termes de découverte scientifique. De nombreuses disciplines peuvent se croiser avec l'IA. Je pense que c'est un domaine qui peut être approfondi. D'un point de vue théorique, je trouve très intéressant que les capacités de l'IA aient complètement dépassé la théorie. Nous ne savons pas comment procéder, manquons d'interprétabilité et ne savons pas comment révéler les relations causales. Notre compréhension du modèle reste incertaine, et de nombreuses pistes de développement restent à explorer. En vision par ordinateur, certains problèmes restent non résolus. De plus, les petites données constituent également un domaine très intéressant et riche en possibilités.
Questionneur 2 : Merci, Professeur Fei-Fei Li, et félicitations pour l'obtention de votre doctorat honorifique de l'Université Yale. J'ai eu l'honneur d'assister à ce moment en personne il y a un mois. Ma question est la suivante : selon vous, l'IAG est-elle plus susceptible d'émerger sous la forme d'un modèle unique et unifié, ou d'un système « modèle-agent » ?
Fei-Fei Li : Deux définitions ont été proposées pour votre question. La première, plus théorique, définit l'IAG comme une intelligence mesurée par un test de QI, et la seconde, plus pragmatique, se concentre sur les tâches qu'un agent intelligent peut accomplir. Franchement, je suis un peu perdu quant à la définition de l'IAG.
En effet, lors de la conférence de Dartmouth en 1956, les fondateurs de l'intelligence artificielle, dont John McCarthy et Marvin Minsky, souhaitaient résoudre le problème des machines capables de « penser », un problème déjà proposé par Alan Turing avant eux. Par conséquent, cette proposition n'est pas un problème d'intelligence artificielle au sens strict, mais une proposition plus large sur l'intelligence. Je ne vois donc pas comment distinguer ce problème fondateur de l'intelligence artificielle du nouveau terme « IAG ».
Pour moi, l'AGI et l'IA sont la même chose, mais je comprends que l'industrie ait tendance à considérer l'AGI comme quelque chose de plus profond que l'IA. J'ai du mal à comprendre cela, car je ne sais pas exactement ce qu'est l'AGI et en quoi elle diffère de l'IA. Si l'on dit que les systèmes actuels de type « AGI » sont plus performants sur certaines tâches que les systèmes d'IA restreints des années 1970, 1980 et 1990, je pense que c'est exact, et que c'est une évolution naturelle du domaine. Mais fondamentalement, je pense que l'essence de l'intelligence artificielle est de créer des machines capables de penser et d'agir comme les humains, voire plus intelligentes que les humains. Je ne sais donc pas comment définir l'AGI, et comme je ne peux pas la définir, je ne peux pas dire s'il s'agit d'un système unique.
Si nous le regardons du point de vue du cerveau, c'est un tout, et nous pouvons l'appeler un système unique, mais ses fonctions sont diverses, et il y a même la zone de Broca dans le cerveau qui est responsable du langage, le cortex visuel pour la vision, le cortex moteur pour le mouvement, etc. Par conséquent, je ne sais pas vraiment comment répondre à cette question.
Questionneur 3 : Bonjour, je m’appelle Yasna. Tout d’abord, je tiens à vous remercier. C’est vraiment inspirant de voir une femme jouer un rôle de premier plan dans ce domaine. En tant que chercheuse, éducatrice et entrepreneuse, j’aimerais savoir, dans le domaine en pleine expansion de l’intelligence artificielle, quel type de personnes devraient, selon vous, poursuivre des études supérieures ?
Fei-Fei Li : C'est une excellente question, et même des parents me l'ont posée. Les études supérieures sont une période de quatre à cinq ans d'intense curiosité.
Vous êtes animé par la curiosité, et cette curiosité est si forte qu'il n'y a pas de meilleur endroit pour l'assouvir qu'ici. C'est différent d'une startup, car dans une startup, on ne peut pas être uniquement motivé par la curiosité. Il faut veiller à ce qu'une startup ne soit pas uniquement motivée par la curiosité, au risque de mécontenter les investisseurs. Elle est davantage axée sur l'atteinte d'objectifs commerciaux, et bien qu'il y ait une part de curiosité, elle n'est pas entièrement motivée par la curiosité. Pour les étudiants de troisième cycle, la curiosité pour résoudre des problèmes ou la capacité à poser des questions est essentielle. Je pense que ceux qui abordent leurs études supérieures avec cette forte curiosité apprécieront vraiment ces quatre ou cinq années. Même si le monde extérieur évolue rapidement, vous serez toujours satisfait d'avoir suivi votre curiosité.
Questionneur 4 : Tout d’abord, je tiens à vous remercier d’avoir pris le temps de partager votre point de vue avec nous. Vous avez mentionné que l’open source a joué un rôle important dans le développement de l’intelligence artificielle. Aujourd’hui, avec la publication et le développement de modèles linguistiques de grande envergure, nous constatons que différentes organisations adoptent des stratégies différentes en matière d’open source. Certaines organisations sont totalement fermées, d’autres appliquent l’intégralité de leur cadre de recherche en open source, tandis que d’autres optent pour des compromis, pondèrent les modèles open source ou adoptent des licences restrictives, etc. J’aimerais donc vous demander ce que vous pensez de ces différentes approches open source. Quelle est, selon vous, la bonne approche ? En tant qu’entreprise d’IA, comment l’open source devrait-il fonctionner ?
Fei-Fei Li : Je pense que lorsqu'il existe différentes approches de l'open source dans l'écosystème, l'environnement global est sain. Je ne suis pas catégorique sur la question de savoir s'il faut privilégier l'open source ou le closed source. Cela dépend de la stratégie commerciale de l'entreprise. Par exemple, Meta (anciennement Facebook) a clairement expliqué pourquoi elle a choisi l'open source. Son modèle économique actuel ne vise pas à générer des profits grâce à des modèles commerciaux, mais à développer l'écosystème en utilisant ces modèles et à attirer davantage de personnes vers sa plateforme. L'open source est donc tout à fait pertinent pour elle. Et pour d'autres entreprises qui tirent réellement profit de ces technologies, une combinaison d'open source et de closed source, fonctionnant par couches, peut être envisagée. Je suis donc ouvert à ces approches.
▲ Le modèle open source lama de Meta figure dans le classement des grands modèles de langage open source Hugging Face
À un niveau plus large, je pense que l'open source doit être protégé, que ce soit dans le secteur public, comme le monde universitaire, ou dans le secteur privé. Si des initiatives en faveur de l'open source sont menées, elles sont cruciales. Elles sont essentielles à l'écosystème des startups et au secteur public. Je pense que ces initiatives doivent être protégées et non ignorées.
Questionneur 5 : Bonjour, je m’appelle Carl, je viens d’Estonie et j’ai une question sur les données. Vous avez évoqué l’évolution de l’apprentissage automatique grâce aux approches basées sur les données, notamment les progrès réalisés sur ImageNet. Vous étudiez actuellement les modèles du monde et vous avez mentionné le manque de données spatiales, qui n’existent pas sur Internet, mais uniquement dans notre cerveau. Comment résolvez-vous ce problème ? Quel est l’axe de vos recherches ? Collectez-vous des données du monde réel ou générez-vous des données synthétiques ? Croyez-vous aux données synthétiques ? Ou préférez-vous les connaissances traditionnelles préalables ? Merci.
Fei-Fei Li : Rejoignez-moi à World Labs, je vous raconterai. En tant qu'entreprise, je ne peux pas trop en dire, mais je pense qu'il est important de reconnaître que nous adoptons une approche hybride. Il est essentiel d'avoir beaucoup de données, mais il est tout aussi important d'avoir des données de haute qualité. Au final, si l'on ne prête pas attention à la qualité des données, le résultat final est un gaspillage de données.
Questionneur 6 : Bonjour, Dr Fei-Fei Li, je m’appelle Annie. Merci beaucoup de nous avoir accordé cet entretien. Dans votre livre, The World, j’ai vu que vous parliez des défis que représente le fait d’être une jeune fille ou une femme immigrée dans les domaines des sciences, de la technologie, de l’ingénierie et des mathématiques (STEM). J’aimerais savoir si vous avez déjà eu le sentiment d’appartenir à une minorité sur le lieu de travail. Si oui, comment avez-vous surmonté ce dilemme ou convaincu les autres ?

Fei-Fei Li : Merci pour votre question. Je vais y répondre avec prudence et attention, car chacun de nous a un parcours différent et une expérience unique. Vous savez, cela n'a presque aucune importance. Nous avons tous des moments où nous nous sentons minoritaires ou seuls. Alors, bien sûr, j'ai ressenti cela.
Parfois, c'est une question de qui je suis, parfois de ma façon de penser, parfois simplement de la couleur des vêtements que je porte, il y a toujours une raison. Mais je tiens à vous encourager à cet égard. C'est peut-être parce que je suis arrivée jeune dans ce pays et que j'ai vécu des expériences. J'ai accepté d'être une femme immigrée. J'ai presque développé une capacité à ne pas prendre les choses trop au sérieux. Je suis ici, comme chacun d'entre vous. Je suis ici pour apprendre, pour faire, pour créer.
Je tiens à dire à chacun d'entre vous que, que vous soyez sur le point de démarrer quelque chose ou que vous soyez déjà en train de le faire, vous aurez des moments de faiblesse ou de confusion. Je le ressens tous les jours, surtout dans la vie d'entrepreneur. Parfois, je me dis : « Oh mon Dieu, je ne sais pas ce que je fais. Ne vous inquiétez pas, concentrez-vous simplement sur ce que vous faites. » Comme pour la descente de gradient, progressez pas à pas vers la solution optimale.
#Bienvenue pour suivre le compte public officiel WeChat d'iFanr : iFanr (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.