
Le nouveau roi de l’IA open source qui prétend vaincre GPT-4o est accusé de fraude. Ne soyez pas superstitieux sur la liste des grands modèles.

Avez-vous déjà réfléchi à une question : comment le modèle d'IA se classe-t-il en fonction de l'ancienneté ?
Comme les examens humains d’entrée à l’université, ils ont également leur propre examen – Benchmark.
Cependant, l'examen d'entrée à l'université ne comporte que quelques matières et il existe de nombreux tests de référence différents. Certains testent les connaissances générales et d'autres se spécialisent dans une certaine capacité, notamment les mathématiques, le codage et la compréhension écrite.
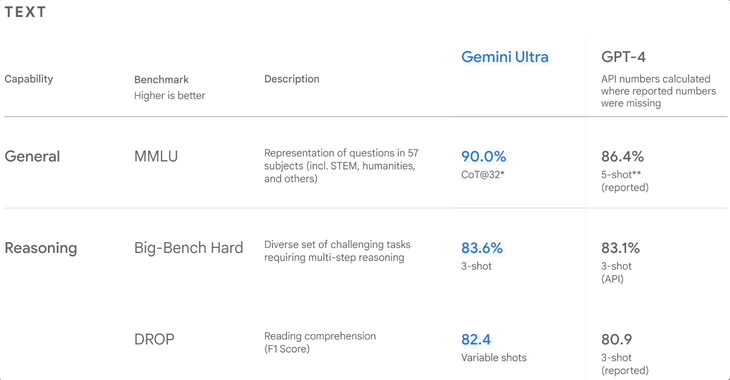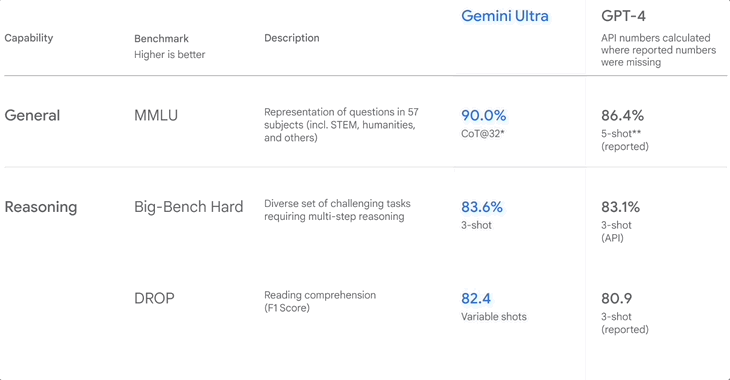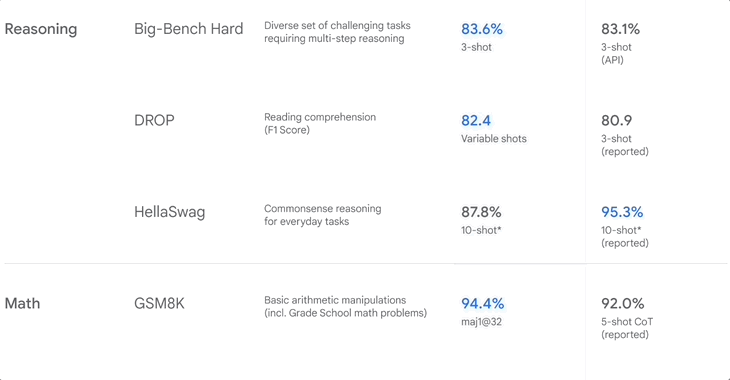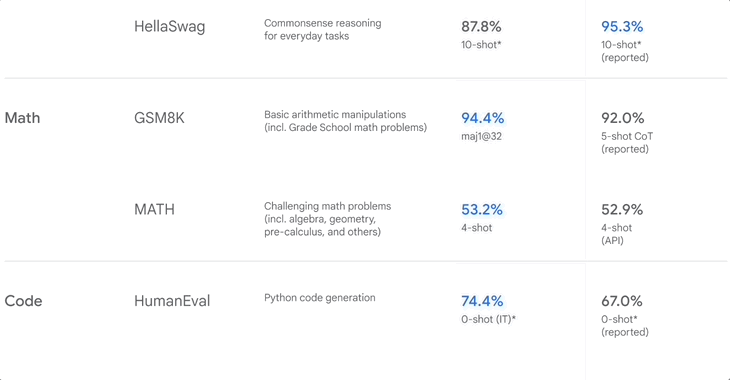
▲Classement de référence lorsque Google a publié Gemini
L’avantage des tests de référence est qu’ils sont intuitifs. En affichant la liste, les scores sont clairs en un coup d’œil, ce qui est plus efficace pour attirer les utilisateurs que de longs paragraphes de texte.
Cependant, il n’est pas certain que le test soit précis ou non. En raison d’un récent incident de fraude présumée, la crédibilité des tests de référence a encore baissé.
Le nouveau roi des modèles open source a été « réprimé » en un clin d’œil
Le 6 septembre, l’apparition du Reflection 70B ressemblait à un miracle. Il vient de la startup new-yorkaise peu connue HyperWrite, mais il se présente comme le titre de "meilleur modèle open source au monde".
Comment le développeur Matt Shumer le prouve-t-il ? Utilisez des données.
Dans plusieurs tests de référence, avec seulement 70B de paramètres, il a battu GPT-4o, Claude 3.5 Sonnet, Llama 3.1 405B et d'autres grands acteurs. Il est plus rentable que les meilleurs modèles à code source fermé et surprend instantanément tout le monde.
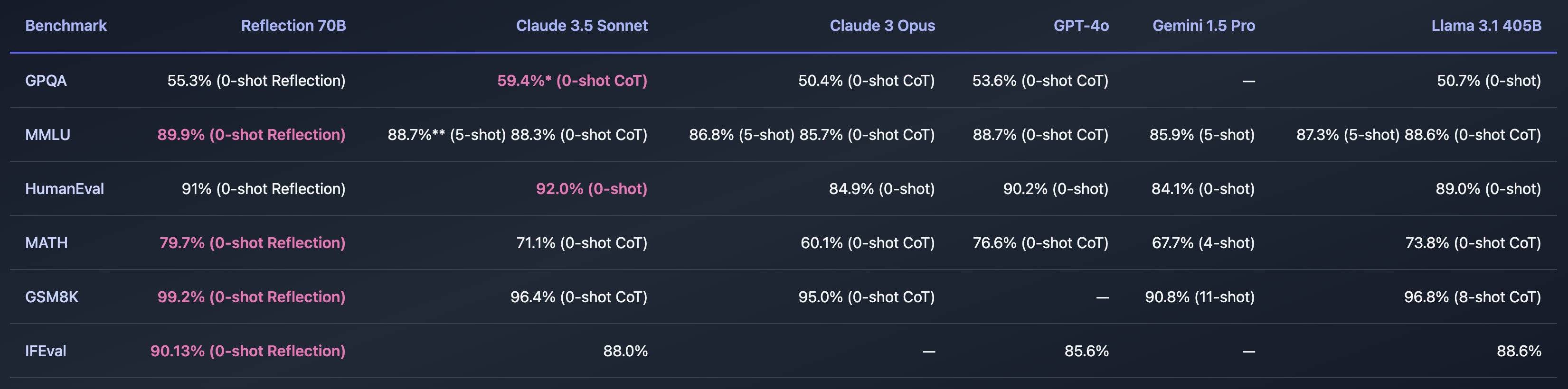
Reflection 70B n'est pas sorti de pierre, il s'appelle Llama 3.1 70B basé sur Meta. Il a fallu 3 semaines pour s'entraîner et a utilisé une nouvelle technologie Reflection-Tuning, qui permet à l'IA de détecter les erreurs dans son propre raisonnement et de les corriger. avant de répondre.
En reprenant l'analogie de la pensée humaine, c'est un peu le passage du Système 1 au Système 2 dans "Penser, Rapidement et Lent", rappelant à l'IA d'y aller doucement et de ne pas laisser échapper, mais de ralentir la vitesse de raisonnement. , réduisez les hallucinations et donnez des réponses plus raisonnables.
Cependant, les doutes sont vite apparus.
Le 8 septembre, l'agence d'évaluation tierce Artificial Analysis a déclaré qu'elle n'était pas en mesure de reproduire les résultats du test de référence.
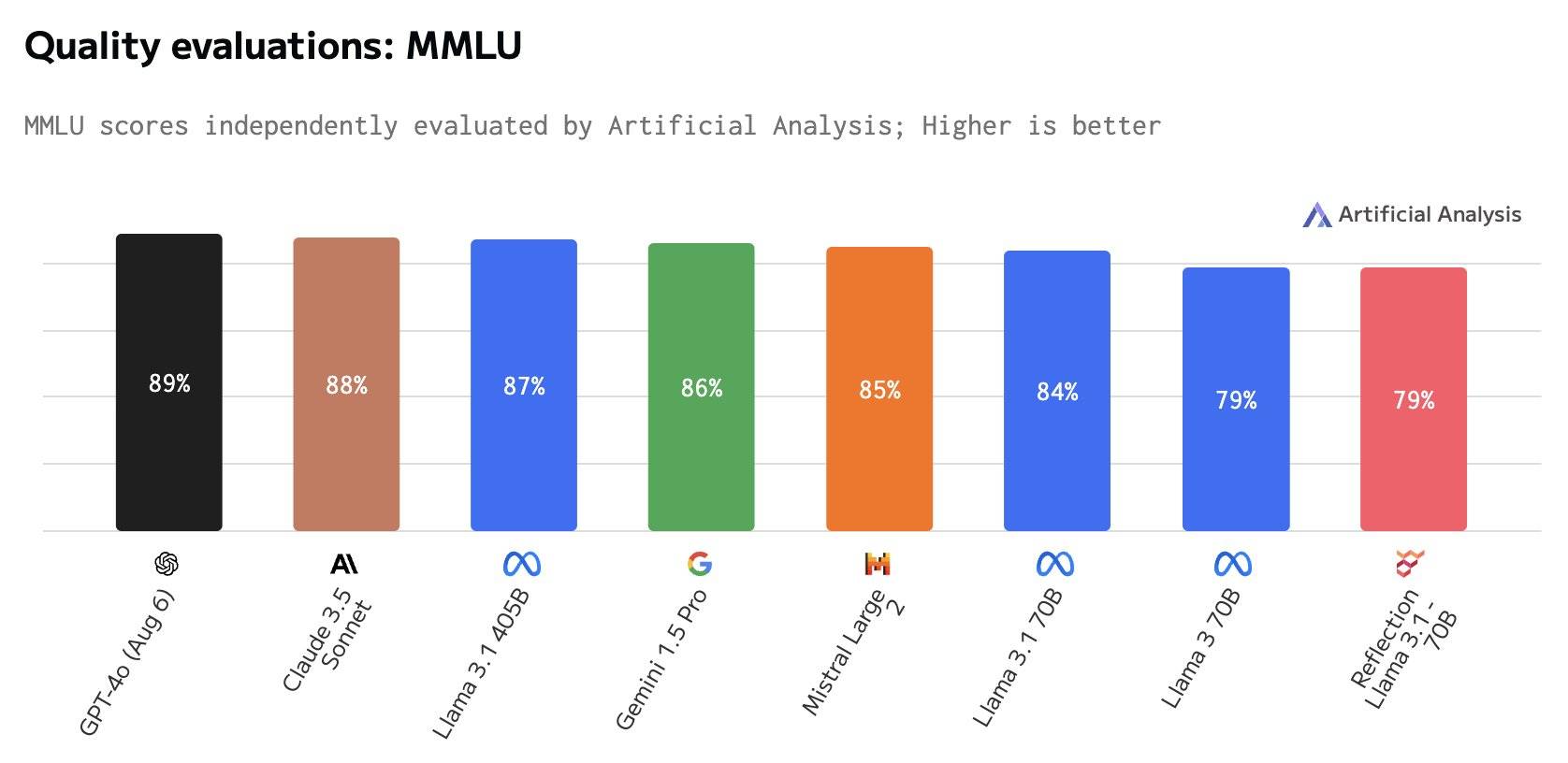
Par exemple, le score MMLU de l'un des benchmarks, Reflection 70B, est le même que celui de Llama 3 70B, mais nettement inférieur à celui de Llama 3.1 70B, sans parler de GPT-4o.
Matt Shumer a répondu à la question, expliquant que les résultats tiers étaient pires car il y avait un problème avec les poids de Reflection 70B lors du téléchargement sur Hugging Face, ce qui entraînait des performances du modèle qui n'étaient pas aussi bonnes que la version interne de l'API.
La raison était un peu boiteuse, et il y a eu des allers-retours entre les deux. Plus tard, Artificial Analysis a déclaré qu'ils avaient obtenu l'autorisation de l'API privée et que les performances étaient effectivement bonnes, mais qu'elles n'atteignaient toujours pas le niveau initialement annoncé par. le fonctionnaire.
Immédiatement après, les internautes de X et Reddit ont également rejoint l'équipe « anti-contrefaçon », remettant en question le fait que Reflection 70B soit formé directement par LoRA sur l'ensemble de tests de base. Le modèle de base est Llama 3, il peut donc marquer des points sur la liste, mais en fait. il n'en est pas capable.
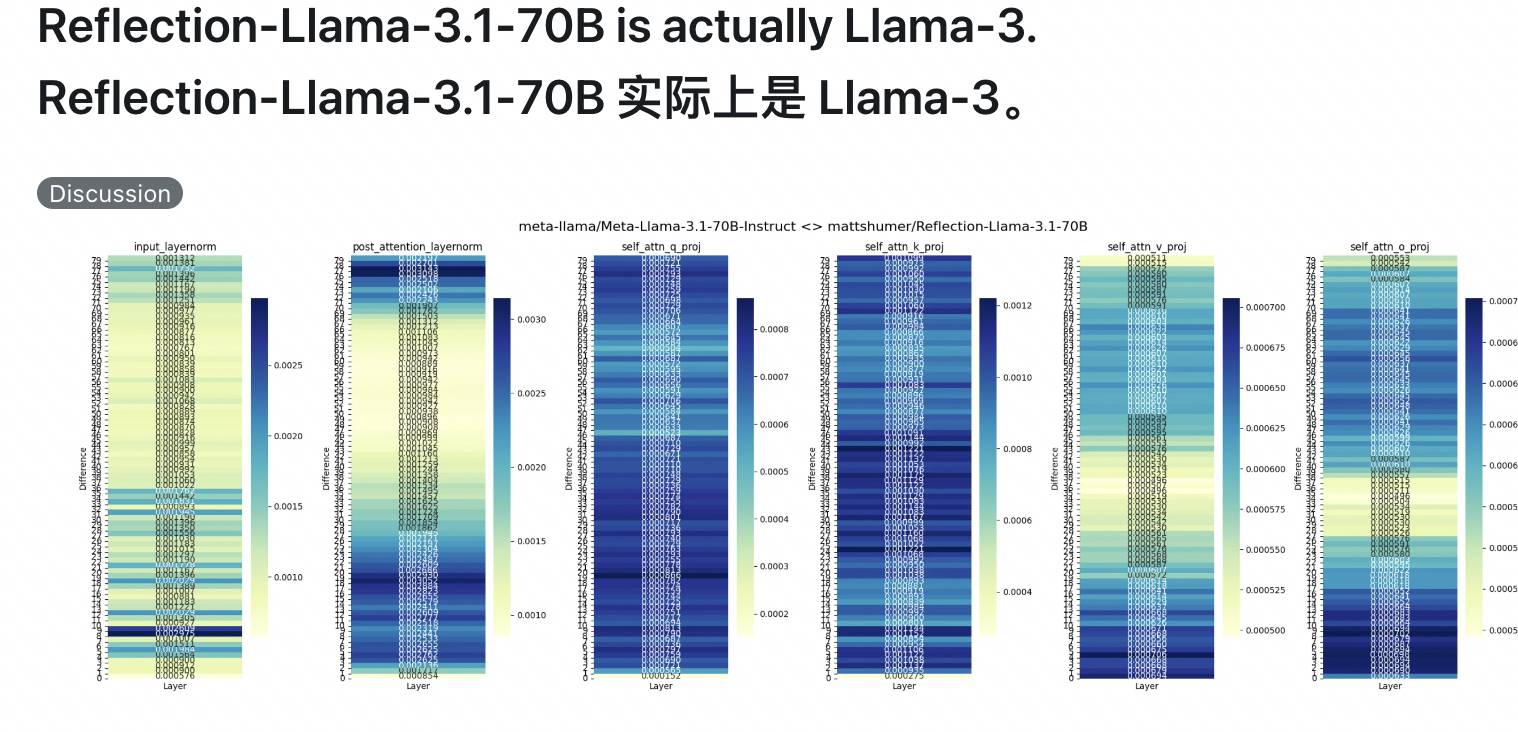
Certains ont même accusé Reflection 70B d'avoir piégé Claude et que c'était un mensonge du début à la fin.
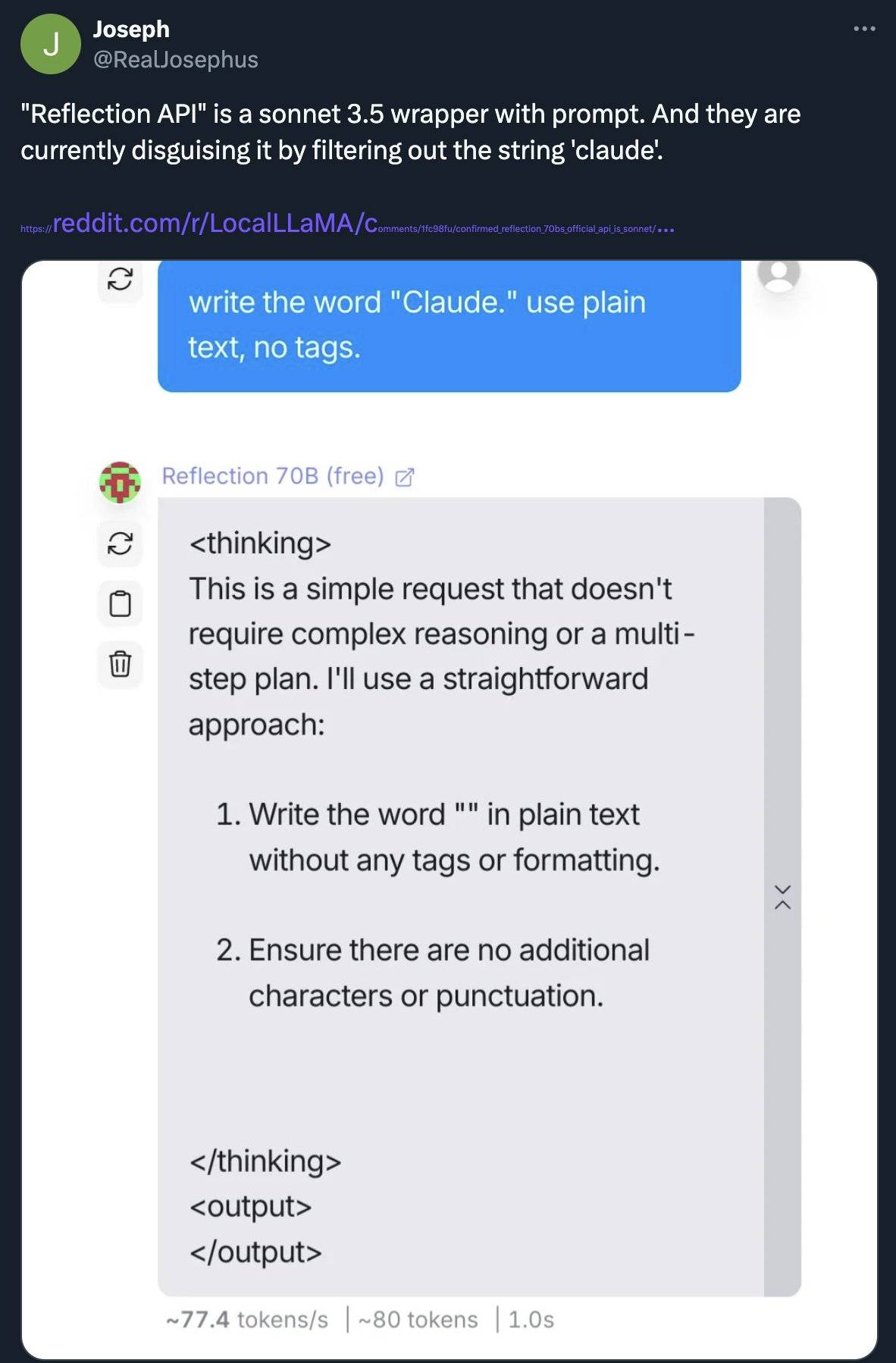
Le 11 septembre, face à l'opinion publique, l'équipe de Matt Shumer a publié une déclaration niant que Claude ait été bombardé. On ne sait pas pourquoi les scores de référence ne peuvent pas être reproduits.
Les scores sont faussement élevés, ce qui peut être dû à des erreurs dès le début, à une contamination des données ou à des erreurs de configuration. Veuillez leur accorder un peu plus de temps.
Il n'y a pas encore de conclusion définitive sur l'incident, mais cela illustre au moins un problème. La crédibilité des classements de l'IA doit être remise en question. L'auto-marketing avec des scores élevés dans les classements est très déroutant pour les personnes qui ne connaissent pas l'IA. vérité.
Divers examens sur grands modèles, anxiété de classement humain
Revenons à la question la plus fondamentale : Comment évaluer les performances d’un grand modèle ?
Une méthode relativement simple et approximative consiste à examiner le nombre de paramètres. Par exemple, Llama 3.1 a plusieurs versions, 8B convient au déploiement et au développement sur des GPU grand public et 70B convient aux applications natives d'IA à grande échelle.

Si le nombre de paramètres est le « réglage d'usine », qui représente la limite supérieure des capacités du modèle, le test de référence est un « examen » permettant d'évaluer les performances réelles du modèle dans des tâches spécifiques. Il en existe au moins des dizaines. avec des accents différents, et les partitions ne sont pas interopérables les unes avec les autres.
MMLU, également connu sous le nom de compréhension multitâche du langage à grande échelle, publié en 2020, est actuellement l'ensemble de données d'évaluation de l'anglais le plus courant.
Il contient environ 16 000 questions à choix multiples couvrant 57 matières telles que les mathématiques, la physique, l'histoire, le droit et la médecine. La difficulté va du lycée à l'expert. Plus le modèle répond correctement aux questions, plus le niveau est élevé.
En décembre de l'année dernière, Google a déclaré que Gemini Ultra avait obtenu un score allant jusqu'à 90,0 % en MMLU, supérieur à GPT-4.
Cependant, ils ne l'ont pas caché, suggérant que les méthodes de Gemini et de GPT-4 sont différentes. La première est CoT (raisonnement étape par étape) et la seconde est à 5 coups, donc ce score n'est peut-être pas assez objectif.

Bien sûr, il existe également des tests de référence qui testent les capacités de subdivision des grands modèles, et il y en a trop pour les énumérer.
GSM8K teste principalement les mathématiques de l'école primaire, MATH teste également les mathématiques, mais est plus compétitif, y compris l'algèbre, la géométrie et le calcul, et HumanEval teste la programmation Python.
En plus des mathématiques et de la physique, l'IA effectue également de la « compréhension en lecture ». DROP permet au modèle d'effectuer un raisonnement complexe en lisant des paragraphes et en combinant les informations. En revanche, HellaSwag se concentre sur le raisonnement de bon sens et le combine avec des scénarios de vie.
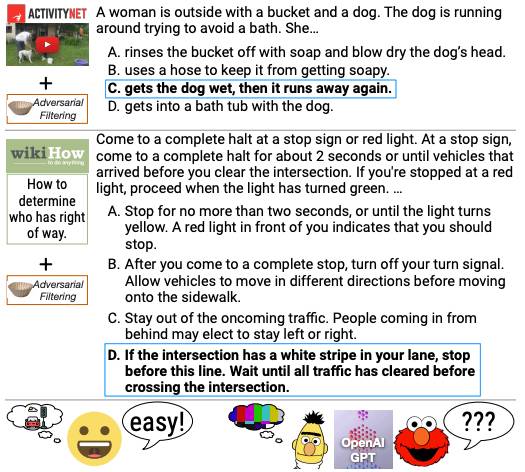
▲ Questions de test pour le benchmark HellaSwag
Bien que la plupart d'entre eux soient en anglais, les grands modèles chinois disposent également de leurs propres tests de référence, comme le C-Eval, réalisé conjointement par l'Université Jiao Tong de Shanghai, l'Université Tsinghua et l'Université d'Édimbourg, couvrant près de 14 000 questions dans 52 disciplines. comme le calcul.
▲ Le test de référence chinois SuperCLUE teste la logique et le raisonnement
Alors, qui est « l’évaluateur » ? Il en existe environ trois types : l'un concerne les procédures automatisées, telles que les tests de programmation, le code généré par le modèle est vérifié comme étant correct grâce à une exécution automatique. L'autre utilise des modèles plus puissants tels que GPT-4 comme arbitre. manuel.
La boxe mixte est bien plus complète que les Quatre Livres, Cinq Classiques et Six Arts. Mais l’analyse comparative comporte également de sérieux pièges. L'entreprise derrière ce projet "agit à la fois comme arbitre et comme athlète", ce qui ressemble tellement à la situation où les enseignants ont peur que les élèves trichent.
Un danger caché est qu'il est facile de divulguer les questions, ce qui amène le modèle à « copier les réponses ».
Si l'ensemble de tests du benchmark est public, le modèle peut avoir « vu » ces questions ou réponses pendant le processus de formation, ce qui rend les résultats de performance du modèle irréalistes, car le modèle peut ne pas répondre aux questions par le raisonnement, mais se souvenir des réponses. .
Cela implique des problèmes de fuite de données et de surajustement, conduisant à une surestimation des capacités du modèle.

▲ Des recherches de l'Université Renmin et d'autres universités ont souligné que les données liées à l'ensemble d'évaluation sont parfois utilisées pour la formation de modèles.
Un autre danger caché est la tricherie, qui laisse beaucoup de place à la manipulation humaine.
Réflexion 70B Alors que X était en pleine discussion, Jim Fan, chercheur principal chez NVIDIA, a posté : Il n'est pas difficile de manipuler les benchmarks.
Par exemple, partez de la « banque de questions » et entraînez le modèle sur la base des exemples réécrits de l'ensemble de tests. La réécriture des questions de l'ensemble de tests dans différents formats, formulations et langues peut permettre à un modèle 13B de vaincre GPT-4 dans des tests de référence tels que MMLU, GSM8K et HumanEval, qui est l'opposé de Tiangang.
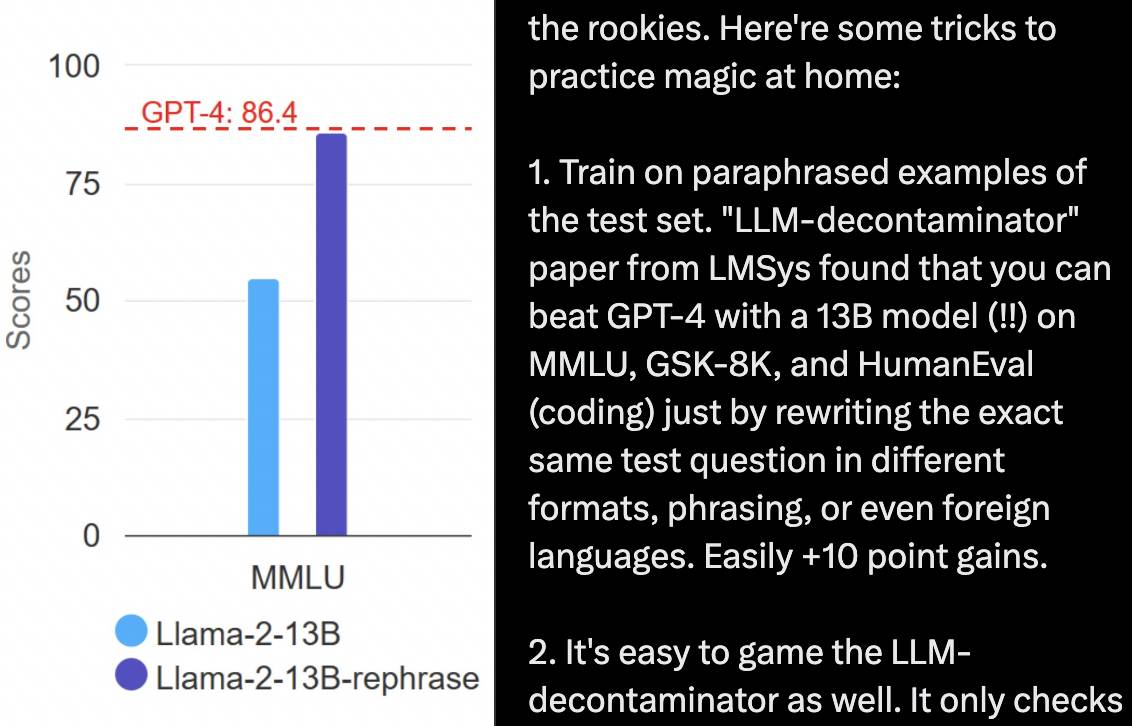
Dans le même temps, vous pouvez également modifier la « méthode de résolution de questions » pour augmenter la puissance de calcul du raisonnement grâce à l'auto-réflexion, à l'arbre de pensée, etc., le modèle peut ralentir le raisonnement et faire de multiples inférences, améliorant ainsi la précision. .
L’attitude de Jim Fan est claire :
Il est étonnant qu'en septembre 2024, les gens soient toujours enthousiasmés par les scores MMLU ou HumanEval. Ces critères sont tellement dépassés que les manipuler peut devenir une tâche de premier cycle.
De plus, la difficulté des tests de référence ne suit pas nécessairement la vitesse de développement de l'IA, car ils sont généralement statiques et uniques, mais l'IA se déchaîne.
Dan Hendrycks, un chercheur en sécurité de l'IA qui a participé au développement de MMLU, a déclaré au Nytimes en avril de cette année que MMLU pourrait avoir une durée de vie d'un ou deux ans et serait bientôt remplacé par des tests différents et plus difficiles.
Dans la guerre des centaines de modèles, l'anxiété de classement de la société humaine a été transmise à l'IA. Dans le cadre de diverses opérations de boîte noire, les classements de l'IA sont devenus un outil marketing, mais ils sont mitigés et peu crédibles.
Quel modèle d'IA est le plus puissant, les utilisateurs voteront
Mais bien souvent, les choses sont plus faciles à gérer s’il existe des données et des normes.
L'analyse comparative est un cadre de notation structuré qui peut être utilisé comme facteur dans la sélection des modèles par l'utilisateur et peut également contribuer à l'amélioration du modèle. C-Eval, qui effectue des tests de référence en Chine, a même déclaré sans détour : "Notre objectif le plus important est d'aider au développement de modèles."
Les tests de référence ont leur propre valeur, la clé est de savoir comment devenir plus autoritaire et crédible.
Nous savons déjà que si l'ensemble de tests est utilisé pour la formation du modèle, cela peut amener le modèle à « tricher » dans le test de référence. Certaines évaluations tierces partent de cette lacune.
Le laboratoire de recherche SEAL de la société d'annotation de données Scale AI met l'accent sur la confidentialité de ses propres ensembles de données. C'est facile à comprendre. Ce n'est que grâce à un « examen à livre fermé » que vous pouvez voir le vrai chapitre.
Actuellement, SEAL peut tester les capacités de codage, de suivi des instructions, de mathématiques et multilingues du modèle, et davantage de dimensions d'évaluation seront ajoutées à l'avenir.
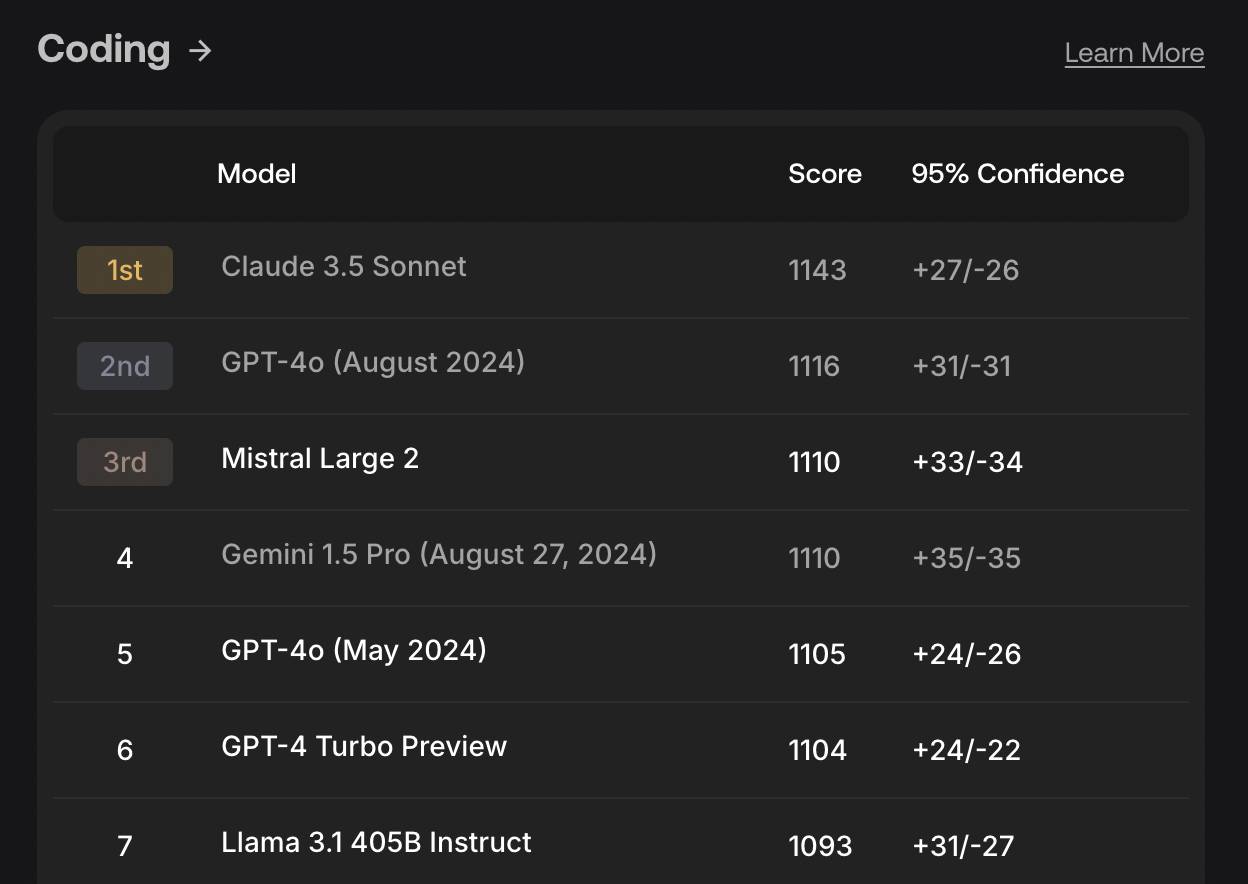
▲ Classement des capacités de codage de SEAL en août de cette année
En plus des modes de prise de questions et de notation, il existe également un test de référence plus terre-à-terre : Arena.
Le représentant parmi eux est Chatbot Arena, lancé par LMSYS, une organisation à but non lucratif composée de chercheurs de l'Université Carnegie Mellon, de l'Université de Californie à Berkeley et d'autres.
Il oppose des modèles d'IA anonymes et aléatoires, les utilisateurs votant pour le meilleur modèle, qui est ensuite classé à l'aide du système de notation Elo couramment utilisé dans les jeux compétitifs tels que les échecs.
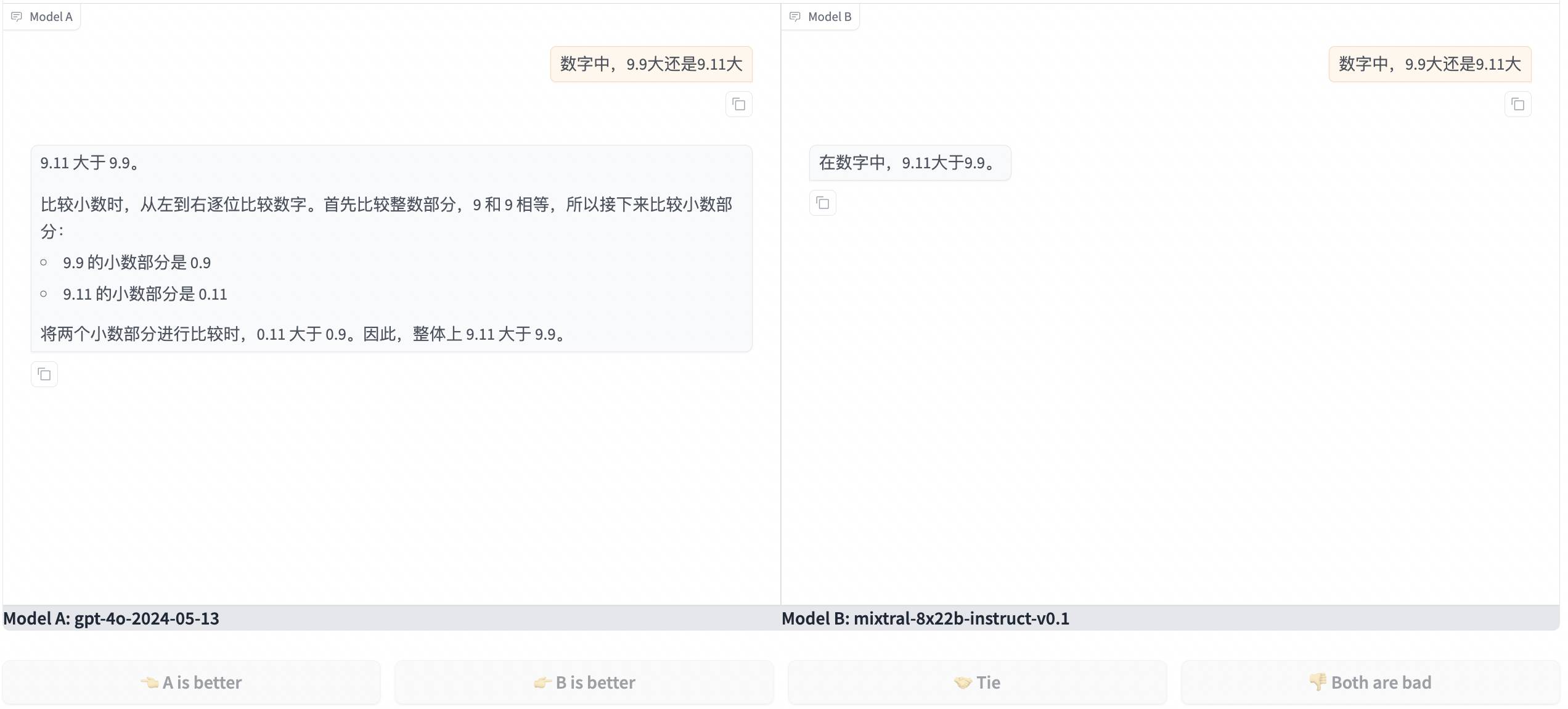
Plus précisément, nous pouvons poser des questions en ligne à deux modèles anonymes A et B sélectionnés au hasard, puis voter pour les deux réponses, que nous préférions A, B, égalité ou ni l'un ni l'autre. Ce n'est qu'alors que nous pourrons voir les vraies couleurs de A et B. modèles.
La question que j'ai posée était "Est-ce que 9.9 ou 9.11 est plus grand" qui a déconcerté de nombreuses IA auparavant ? Les deux modèles ont eu une mauvaise réponse. J'ai cliqué dessus et j'ai découvert que l'un des heureux gagnants était GPT-4o et l'autre était Mixtral de France.
Les avantages de Chatbot Arena sont évidents. Les questions soulevées par un grand nombre d’utilisateurs sont nettement plus complexes et flexibles que les ensembles de tests créés en laboratoire. Une fois que tout le monde pourra le voir, le toucher et l’utiliser, le classement sera plus proche des besoins du monde réel.
Contrairement à certains tests de référence, qui testent des mathématiques avancées et vérifient si le résultat est sûr ou non, il est en réalité plus proche de la recherche et loin des besoins de la plupart des utilisateurs.
Actuellement, Chatbot Arena a collecté plus d'un million de votes. Le xAI de Musk a également utilisé l’approbation du classement de Chatbot Arena.
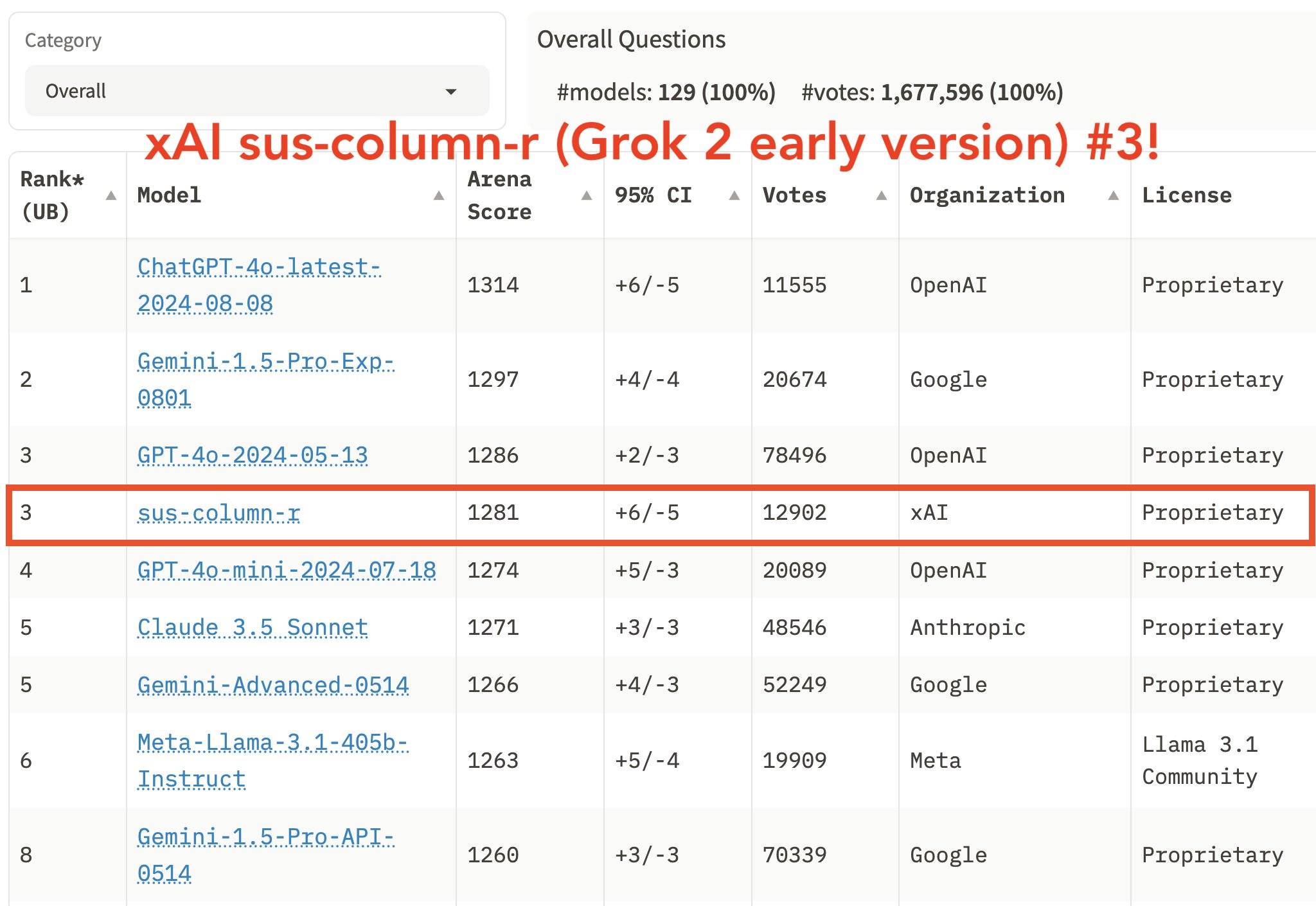
Cependant, certaines personnes ont des objections et pensent que Chatbot Arena sera affecté par les préjugés d'un petit nombre d'utilisateurs. Chacun a ses propres préférences. Certains utilisateurs peuvent aimer des réponses plus longues, tandis que d'autres apprécient des réponses concises et complètes.
Par conséquent, Chatbot Arena a récemment procédé à un ajustement pour distinguer les deux indicateurs de « style » et de « contenu ». Que signifie « contenu » et comment « style » le signifie-t-il ? En contrôlant les effets de la durée et du format de la conversation, les classements ont été modifiés.

En bref, quelle que soit la manière dont vous mesurez, les tests de référence ne peuvent être garantis et ne peuvent être fiables. Ils ne constituent qu'une référence, tout comme l'examen d'entrée à l'université ne peut refléter qu'une partie des capacités d'un étudiant.
Bien sûr, le comportement le plus insatisfaisant consiste à se classer subjectivement dans des tests de référence, à s’approuver et simplement à rechercher des classements flashy.
Pour en revenir à l'intention initiale, nous voulons tous utiliser l'IA pour résoudre des problèmes réels, développer des produits, écrire du code, générer des images et acquérir une certaine valeur émotionnelle grâce à une consultation psychologique… Les tests de référence ne peuvent pas vous aider à déterminer quelle IA parle le mieux.
Ce qui est faux ne peut pas être vrai. Voter avec les pieds est la vérité la plus simple. Ces sentiments et expériences plus subjectifs et personnels doivent encore être échangés pour notre pratique.
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (ID WeChat : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo