
Les talents les plus chers aux États-Unis sont désormais les talents chinois en IA : l’Université Tsinghua, l’Université de Pékin et l’Académie chinoise des sciences « dominent » le cercle de l’IA de la Silicon Valley

Ces deux dernières semaines, ce qui a le plus attiré l'attention dans le secteur de l'IA, ce ne sont pas les produits, mais les personnes. Souvent, à mon réveil, la même nouvelle s'affiche sur mon fil d'actualité : un autre expert en IA a été débauché.
Les meilleurs talents de l’IA deviennent les atouts les plus rares et les plus efficaces en termes de marque dans le domaine de l’IA.
Au cœur de cette vague de flux de talents, nous avons découvert un détail particulièrement frappant : parmi les membres clés qui ont dirigé la recherche et le développement de grands modèles tels que ChatGPT, Gemini et Claude, la proportion de scientifiques chinois était étonnamment élevée.
Ce changement ne s'est pas produit soudainement. Face à la vague d'IA qui a émergé ces dernières années, la proportion de chercheurs chinois de haut niveau en IA aux États-Unis n'a cessé d'augmenter. Selon le rapport 2.0 de l'enquête mondiale sur le suivi des talents en intelligence artificielle publié par MacroPolo, la proportion de chercheurs chinois de haut niveau en IA est passée de 29 % à 47 % entre 2019 et 2022.
Le rapport d'étude de fond sur l'équipe ChatGPT publié par Zhipu Research révèle que parmi les 87 membres de l'équipe principale de ChatGPT, 9 sont chinois, soit plus de 10 %. Nous avons donc également réexaminé les profils des chercheurs chinois en IA qui ont récemment suscité un vif intérêt au sein des plus grandes entreprises de la Silicon Valley, et tenté d'en résumer quelques caractéristiques :
1️⃣ Diplômés d'universités prestigieuses, ils possèdent de solides compétences académiques. La plupart ont suivi des cours de premier cycle dans des universités prestigieuses telles que l'Université Tsinghua, l'Université de Pékin, l'Université des sciences et technologies de Chine et l'Université du Zhejiang. La plupart ont une formation en informatique ou en mathématiques. Pour leurs études supérieures, ils s'orientent généralement vers le MIT, Stanford, Berkeley, Princeton, l'UIUC et d'autres universités prestigieuses. Presque tous ont publié des articles très cités lors de conférences prestigieuses (NeurIPS, ICLR, SIGGRAPH, etc.).
2️⃣ Jeunes et productifs, la période d'émergence se concentre après 2020, et la tranche d'âge se situe principalement entre 30 et 35 ans. Les cycles de master et de doctorat coïncident avec l'essor mondial de l'apprentissage profond, avec une solide base académique et une familiarité avec les systèmes d'ingénierie et le travail en équipe. La première étape de la carrière de nombreux individus consiste à contacter les produits ou plateformes d'IA de grandes entreprises ou au service de larges groupes de personnes, avec un point de départ plus élevé et un rythme plus soutenu.
3️⃣ Solide expérience multimodale, après avoir abordé la formation du modèle Leur orientation de recherche se concentre généralement sur un système de raisonnement unifié à travers les modalités (texte, parole, image, vidéo, action), y compris des détails spécifiques tels que RLHF, distillation, alignement, modélisation des préférences humaines et évaluation de l'intonation de la parole.
4️⃣ Même s'il se déplace fréquemment, il ne sera fondamentalement pas hors de l'écosystème
Google, Meta, Microsoft, Nvidia, Anthropic, OpenAI… Leur mobilité s’étend des startups aux géants de l’IA, mais leurs sujets de recherche et leur accumulation technologique tendent à rester cohérents et ils ne changent fondamentalement pas de voie.
OpenAI → Méta
Shuchao Bi
Shuchao Bi est diplômé du département de mathématiques de l'Université du Zhejiang, puis est allé à l'Université de Californie à Berkeley pour poursuivre ses études, où il a obtenu une maîtrise en statistiques et a poursuivi un doctorat en mathématiques.
De 2013 à 2019, il a occupé le poste de directeur technique chez Google, où ses principales contributions ont inclus la création d'un système de recommandation d'apprentissage profond en plusieurs étapes qui a considérablement augmenté les revenus publicitaires de Google (en milliards de dollars).
De 2019 à 2024, il a dirigé Shorts Exploration, période durant laquelle il a co-créé et dirigé le système de recommandation et de découverte de vidéos Shorts, et a construit et développé une équipe d'apprentissage automatique à grande échelle couvrant les systèmes de recommandation, les modèles de notation, la découverte interactive, la confiance et la sécurité, et d'autres domaines.
Après avoir rejoint OpenAI en 2024, il a principalement dirigé l'organisation post-formation multimodale et est le co-créateur du modèle de parole GPT-4o et o4-mini
Durant cette période, il a principalement promu le RLHF, le raisonnement image/parole/vidéo/texte, les agents multimodaux, la parole multimodale (VS2S), le modèle de base vision-langage-action (VLA), les systèmes d'évaluation intermodaux, etc. Il a également impliqué le raisonnement en chaîne multimodal, l'évaluation de l'intonation et du naturel de la parole, la distillation multimodale et l'optimisation auto-supervisée. Son objectif principal est de construire un agent d'IA multimodal plus général grâce à la post-formation.
Huiwen Chang
Diplômé du département d'informatique (promotion Yao) de l'université Tsinghua en 2013, Huiwen Chang a ensuite poursuivi ses études à l'université de Princeton, aux États-Unis, pour préparer un doctorat en informatique. Ses recherches portent sur le transfert de styles d'images, les modèles génératifs et le traitement d'images. Il a obtenu une bourse de Microsoft Research.
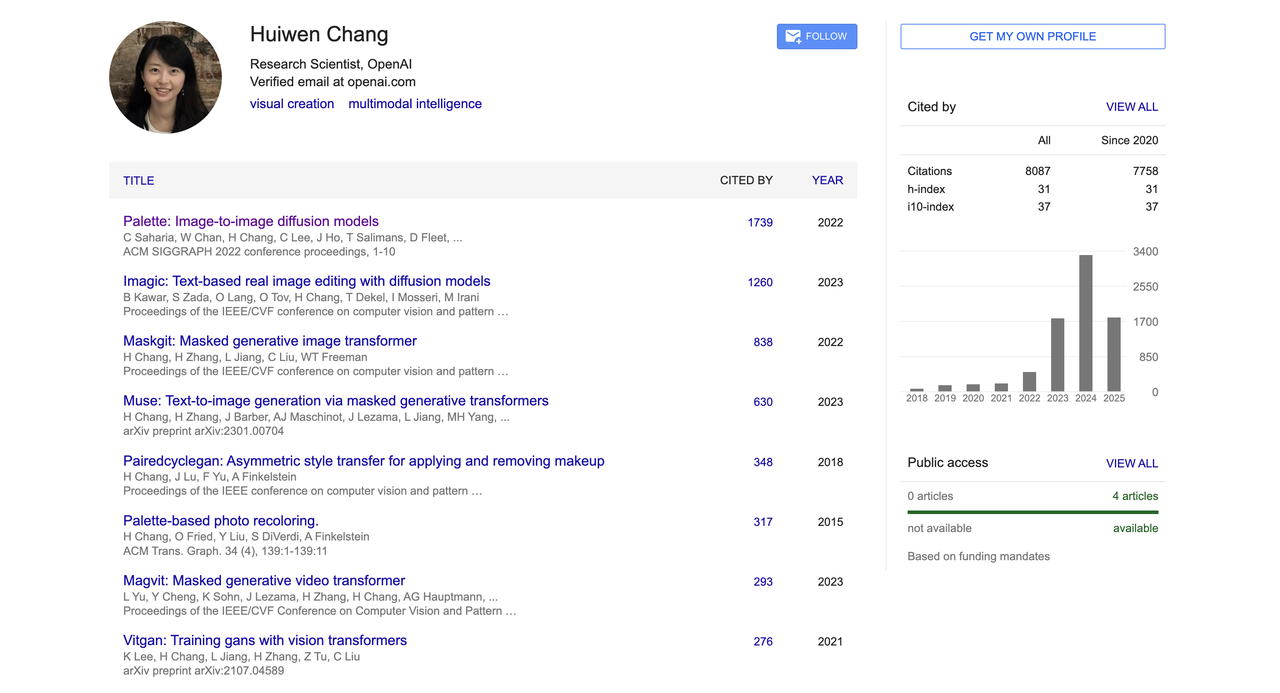
Avant de rejoindre OpenAI, elle a travaillé comme chercheuse scientifique senior chez Google pendant plus de six ans et s'est consacrée depuis longtemps à la recherche sur les modèles génératifs et la vision par ordinateur. Elle a inventé les architectures de conversion de texte en image MaskGIT et Muse chez Google Research.
Les premières générations de texte en image reposaient principalement sur des modèles de diffusion (tels que DALL·E 2 et Imagen). Bien que ces modèles offrent une qualité de génération élevée, leur vitesse d'inférence est lente et leur coût d'apprentissage est élevé. MaskGIT et Muse, en revanche, utilisent l'approche « discrétisation + génération parallèle », qui améliore considérablement l'efficacité.

MaskGIT est un nouveau point de départ pour la génération d'images non autorégressives, et Muse est un exemple représentatif qui étend cette méthode à la génération d'images textuelles. Moins connus que Stable Diffusion, ils constituent néanmoins des piliers techniques essentiels dans les systèmes universitaires et d'ingénierie.
En outre, elle est également l'une des co-auteures de l'article sur le modèle de diffusion de premier plan « Palette : modèles de diffusion d'image à image ».
Cet article a été publié au SIGGRAPH 2022. Il proposait un cadre unifié de traduction d'image à image et surpassait les normes GAN et de régression dans de nombreuses tâches telles que la restauration, la colorisation et la complétion d'images. Il a été cité plus de 1 700 fois à ce jour et est devenu l'une des réalisations les plus représentatives dans ce domaine.
Depuis juin 2023, elle a rejoint l'équipe multimodale d'OpenAI et a co-développé la fonction de génération d'images GPT-4o, continuant à promouvoir la recherche et la mise en œuvre dans des directions de pointe telles que la génération d'images et la modélisation multimodale.

Ji Lin
Ji Lin se consacre principalement à la recherche sur l'apprentissage multimodal, les systèmes de raisonnement et les données synthétiques. Il a contribué à plusieurs modèles clés, notamment GPT-4o, GPT-4.1, GPT-4.5, o3/o4-mini, Operator et le modèle de génération d'images 4o.
Il est diplômé de l'Université Tsinghua avec une licence en génie électronique (2014-2018) et a obtenu son doctorat en génie électrique et informatique du MIT, avec comme superviseur le célèbre universitaire Prof. Song Han.
Au cours de ses études doctorales, ses recherches se sont concentrées sur des domaines clés tels que la compression de modèles, la quantification, les modèles de langage visuel et le raisonnement clairsemé.
Avant de rejoindre OpenAI en 2023, il a travaillé comme chercheur stagiaire chez NVIDIA, Adobe et Google, et s'est engagé depuis longtemps dans la recherche sur la compression des réseaux neuronaux et l'accélération de l'inférence au MIT, accumulant une base théorique approfondie et une expérience pratique de l'ingénierie.
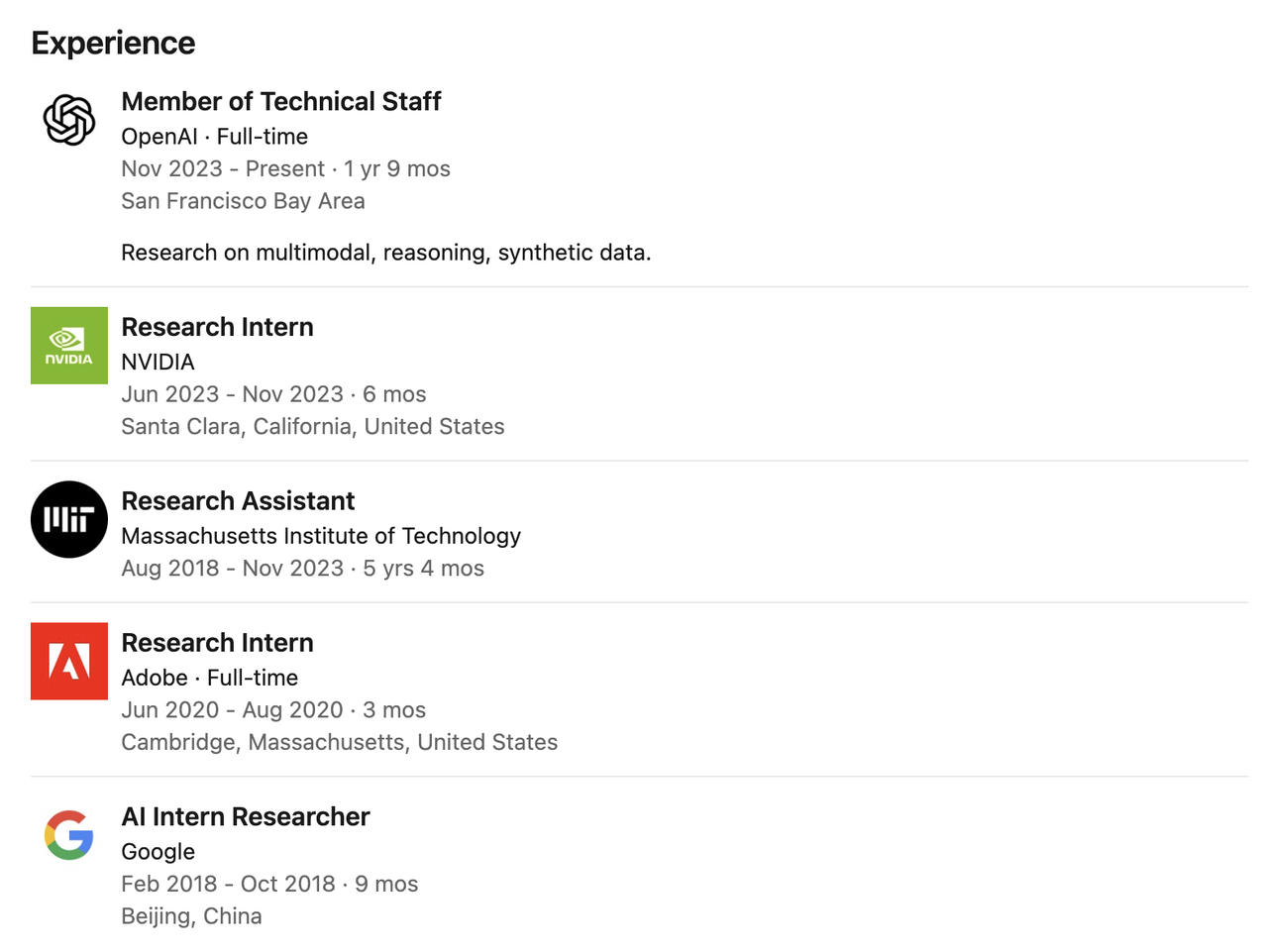
Dans le domaine académique, il a publié de nombreux articles à fort impact dans les domaines de la compression de modèles, de la quantification et du pré-entraînement multimodal, avec plus de 17 800 citations sur Google Scholar. Parmi ses réalisations les plus marquantes figurent le modèle de compréhension vidéo TSM, la méthode de quantification sensible au matériel AWQ, SmoothQuant et le modèle de langage visuel VILA.
Il est également l'un des principaux auteurs de la documentation technique du système GPT-4o (comme la carte système GPT-4o) et a remporté le prix du meilleur article MLSys 2024 pour son article AWQ.
Hong Yu Ren
Hongyu Ren a obtenu sa licence en informatique et technologie de l'Université de Pékin (2014-2018) et son doctorat en informatique de l'Université de Stanford (2018-2023).
Il a reçu de nombreuses bourses, dont une bourse de doctorat d'Apple, de Baidu et de la Fondation SoftBank Masason. Ses recherches portent sur les grands modèles de langage, le raisonnement par graphes de connaissances, l'intelligence multimodale et l'évaluation de modèles de base.
Avant de rejoindre OpenAI, il a effectué plusieurs stages chez Google, Microsoft et NVIDIA. Par exemple, alors qu'il était chercheur stagiaire chez Apple en 2021, il a participé à la construction du système de questions-réponses Siri.
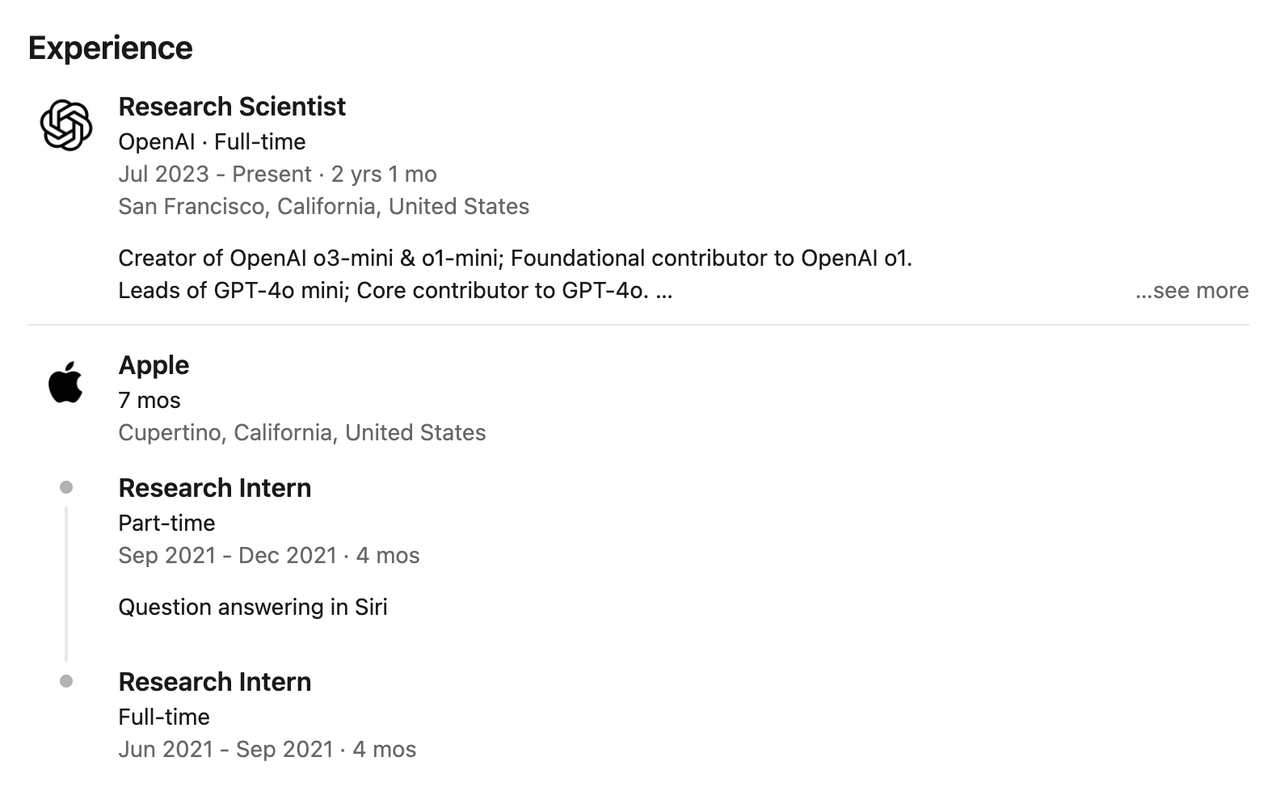
Après avoir rejoint OpenAI en juillet 2023, Hongyu Ren a participé à la construction de plusieurs modèles de base tels que GPT-4o, 4o-mini, o1-mini, o3-mini, o3 et o4-mini, et a dirigé l'équipe post-formation.
Selon ses propres termes : « J’apprends aux modèles à penser plus vite, plus intensément et plus précisément. »
Dans le domaine académique, ses citations totales sur Google Scholar dépassent les 17 742 fois, et ses articles les plus cités incluent : « On the Opportunities and Risks of Foundation Models » (cité 6 127 fois) ; l'ensemble de données « Open Graph Benchmark » (OGB) (cité 3 524 fois), etc.
Jiahui Yu
Jiahui Yu est diplômé de la classe junior de l'Université des sciences et technologies de Chine avec une licence en informatique, puis a obtenu un doctorat en informatique de l'Université de l'Illinois à Urbana-Champaign (UIUC).
Ses domaines de recherche comprennent l’apprentissage profond, la génération d’images, les architectures de grands modèles, le raisonnement multimodal et le calcul haute performance.

Durant son mandat chez OpenAI, Jiahui Yu a été chef de l'équipe de perception, dirigeant le développement de projets importants tels que le module de génération d'images GPT-4o, GPT-4.1, o3/o4-mini, et a proposé et mis en œuvre le système de perception « Penser avec des images ».
Auparavant, il a travaillé chez Google DeepMind pendant près de quatre ans, période durant laquelle il a été l'un des principaux contributeurs à l'architecture et à la modélisation PaLM-2 et a codirigé le développement du modèle multimodal Gemini. Il est l'un des piliers techniques les plus importants de la stratégie multimodale de Google.
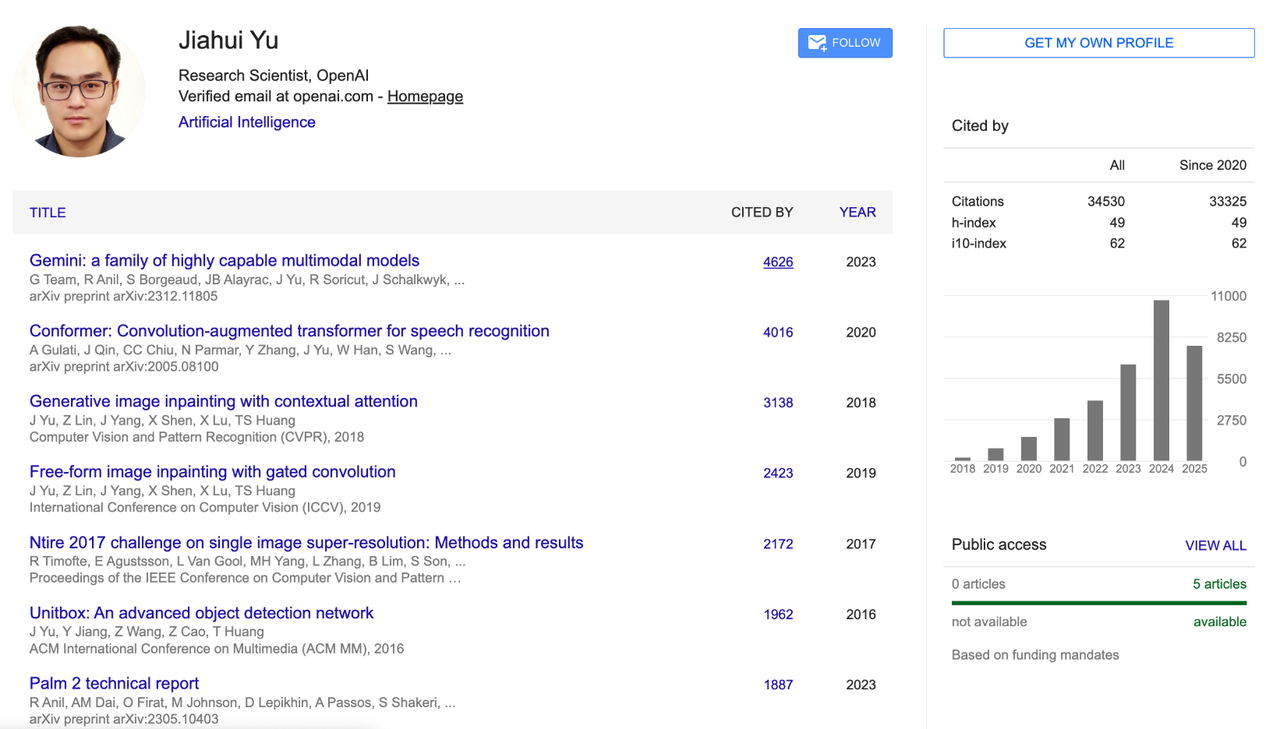
Il a également effectué des stages dans de nombreuses institutions, dont NVIDIA, Adobe, Baidu, Snap, Megvii et Microsoft Research Asia. Ses recherches portent sur le GAN, la détection d'objets, la conduite autonome, la compression de modèles, la restauration d'images et les systèmes d'apprentissage profond à grande échelle.
Jiahui a été cité plus de 34 500 fois sur Google Scholar, avec un indice h de 49. Ses résultats de recherche représentatifs incluent le modèle de base CoCa pour l'alignement image-texte, le modèle de génération de texte en image Parti, la conception de réseau neuronal évolutif BigNAS et la technologie de restauration d'image DeepFill v1 et v2, qui sont largement utilisés dans Adobe Photoshop.
Shengjia Zhao
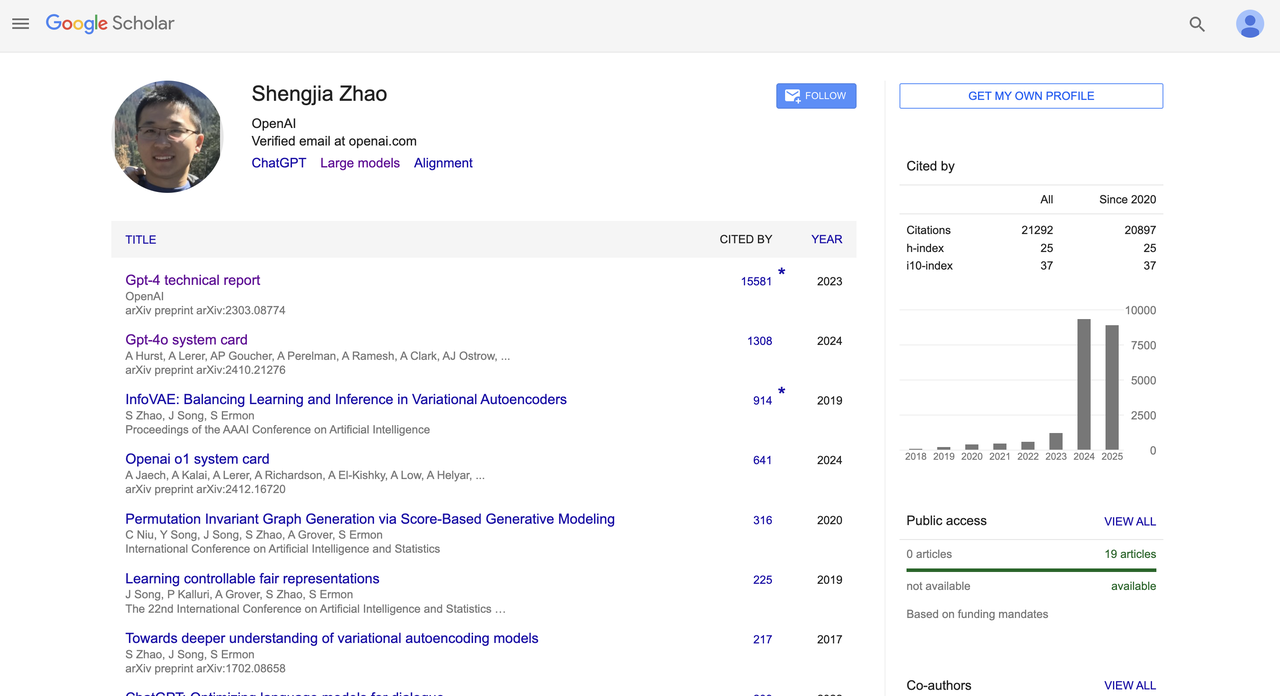
Shengjia Zhao est diplômé du département d'informatique de l'université Tsinghua. Il a effectué un échange universitaire à l'université Rice aux États-Unis, puis a obtenu un doctorat en informatique à l'université Stanford. Il s'est concentré sur la recherche en architecture de grands modèles, le raisonnement multimodal et l'alignement.
En 2022, il a rejoint OpenAI en tant que membre principal de la R&D et a été fortement impliqué dans la conception des systèmes GPT-4 et GPT-4o. Il a dirigé la R&D de ChatGPT, GPT-4, tous les mini-modèles, 4.1 et o3, et a également dirigé l'équipe de données synthétiques d'OpenAI.
Il est co-auteur du « Rapport technique GPT-4 » (cité plus de 15 000 fois) et de la « Carte système GPT-4o » (citée plus de 1 300 fois), et a participé à la rédaction de plusieurs cartes système (comme OpenAI o1). Il est l'un des principaux contributeurs à la standardisation et à l'ouverture des modèles de base d'OpenAI.
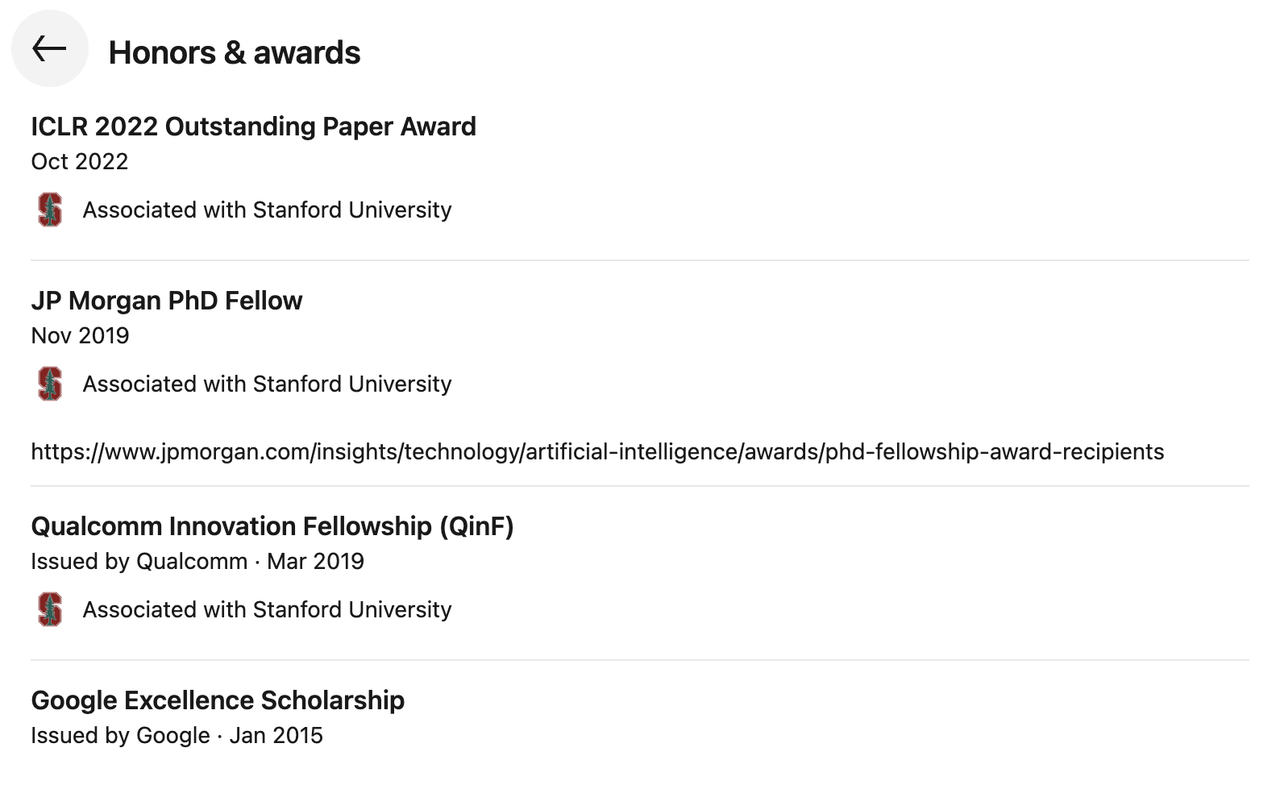
En termes de performances académiques, il compte plus de 21 000 citations Google Scholar au total et un indice h de 25. Il a remporté de nombreux prix, notamment le prix ICLR 2022 Outstanding Paper Award, le JP Morgan PhD Fellow, le Qualcomm Innovation Fellowship (QinF) et le Google Excellence Scholarship.
Google → Méta
Pei Sun
En 2009, Pei Sun a obtenu une licence à l'Université Tsinghua, puis a poursuivi ses études de master et de doctorat à l'Université Carnegie Mellon. Elle a obtenu son master avec succès et a choisi d'abandonner ses études en cours de doctorat.
Il a été chercheur en chef chez Google DeepMind, où il s'est concentré sur le post-entraînement, la programmation et le raisonnement du modèle Gemini. Il est l'un des principaux contributeurs au post-entraînement, à la construction de mécanismes de réflexion et à l'implémentation du code de la série de modèles Gemini (notamment Gemini 1, 1.5, 2 et 2.5).
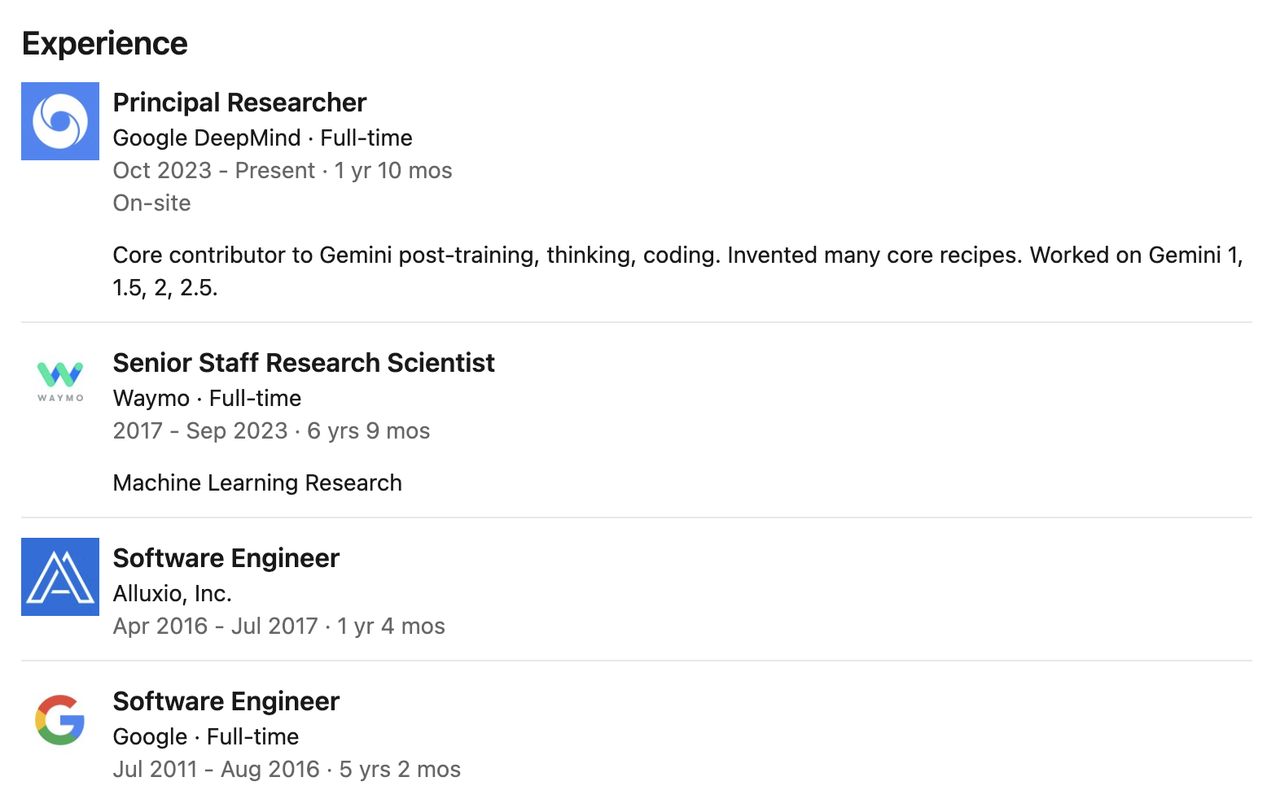
Avant de rejoindre DeepMind, Pei a travaillé chez Waymo pendant près de sept ans en tant que chercheur scientifique senior, dirigeant le développement de deux générations de modèles de perception de base de Waymo et jouant un rôle clé dans l'évolution des systèmes de perception de conduite autonome.
Auparavant, il a travaillé comme ingénieur logiciel chez Google pendant plus de cinq ans, puis a rejoint la société de stockage distribué Alluxio en tant qu'ingénieur pendant plus d'un an, participant à la recherche et au développement de l'architecture système.

Nexusflow → NVIDIA
Banghua Zhu
Banghua Zhu est diplômé du département de génie électronique de l'université Tsinghua, puis s'est rendu à l'université de Californie à Berkeley pour poursuivre un doctorat en génie électrique et en informatique, sous la tutelle des célèbres universitaires Michael I. Jordan et Jiantao Jiao.

Ses recherches portent sur l'amélioration de l'efficacité et de la sécurité des modèles fondamentaux, l'intégration des méthodes statistiques à la théorie de l'apprentissage automatique et la création d'ensembles de données open source et d'outils accessibles au public. Ses centres d'intérêt incluent également la théorie des jeux, l'apprentissage par renforcement, l'interaction homme-machine et la conception de systèmes d'apprentissage automatique.
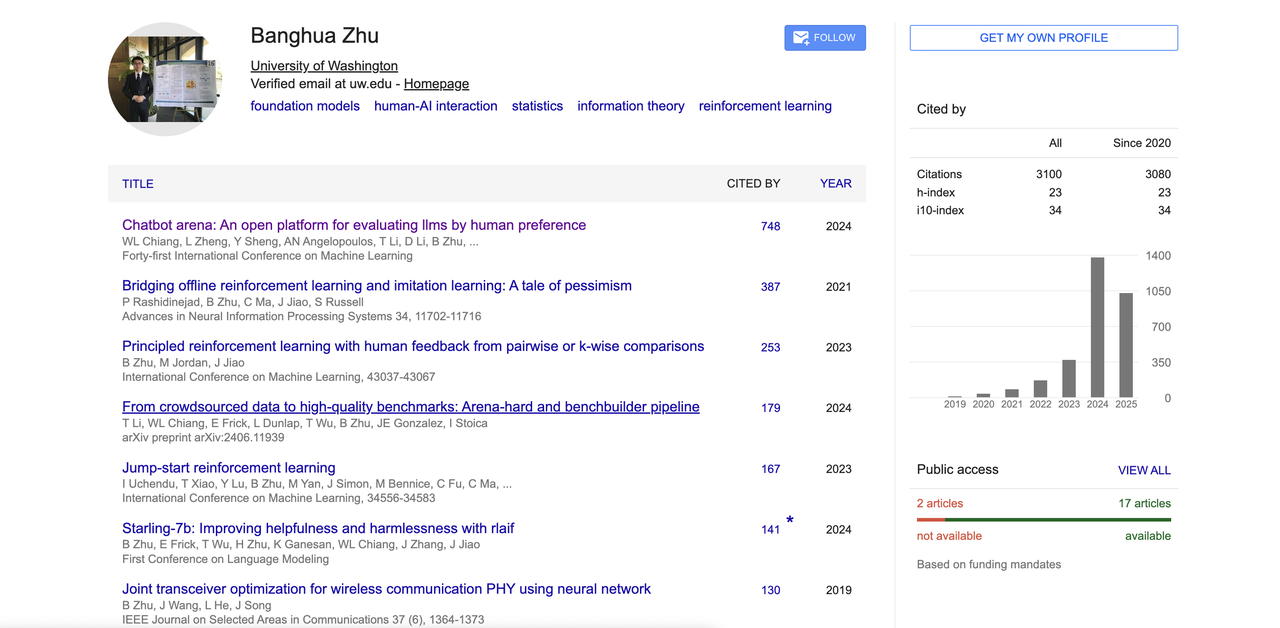
Son article représentatif « Chatbot Arena » a proposé une grande plate-forme d'évaluation de modèles pilotée par les préférences humaines, qui est devenue l'une des références importantes dans le domaine du LLM.
En outre, il a également apporté des contributions à RLHF, à l'alignement du feedback humain, aux modèles d'alignement open source, etc. Son Google Scholar montre que le nombre total de citations dépasse 3 100 et que l'indice h est de 23. Il est également l'un des principaux auteurs de nombreux projets open source populaires tels que la grande arène de modèles « Chatbot Arena », « Benchbuilder » et « Starling ».

Il a été stagiaire de recherche chez Microsoft et étudiant-chercheur chez Google. Il a cofondé la start-up d'IA Nexusflow. En juin dernier, il a annoncé son arrivée au sein de l'équipe Star Nemotron de NVIDIA en tant que directeur de recherche scientifique. Il rejoindra également l'Université de Washington en tant que professeur adjoint cet automne.
Selon le communiqué, il participera à des projets tels que la formation post-modèle, l'évaluation, l'infrastructure d'IA et la construction d'agents intelligents chez NVIDIA, en mettant l'accent sur une collaboration approfondie avec les développeurs et le monde universitaire, et prévoit d'ouvrir les résultats liés à la source.
Jian Tao Jiao
Jiantao Jiao est professeur adjoint aux départements de génie électrique, d'informatique et de statistiques de l'Université de Californie à Berkeley.
Il a obtenu son doctorat en génie électrique de l'Université de Stanford en 2018 et est actuellement codirecteur ou membre de plusieurs centres de recherche, dont le Berkeley Center for Theoretical Learning (CLIMB), le Berkeley Artificial Intelligence Research Center (BAIR Lab), le Laboratory for Information and Systems Science (BLISS) et le Center for Decentralized Intelligence (RDI).
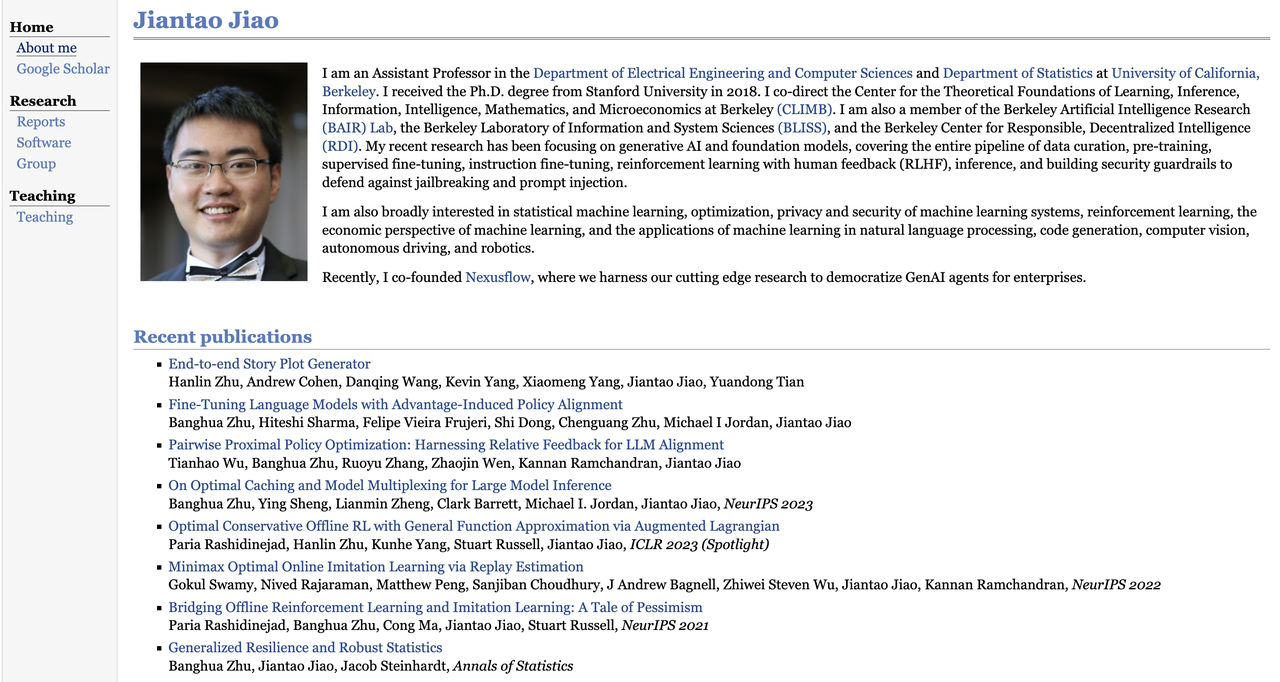
Ses recherches portent sur l'IA générative et les modèles fondamentaux. Il s'intéresse également à l'apprentissage automatique statistique, à la théorie de l'optimisation, à la confidentialité et à la sécurité des systèmes d'apprentissage par renforcement, à la conception de mécanismes économiques, au traitement du langage naturel, à la génération de code, à la vision par ordinateur, à la conduite autonome et à la robotique.
Comme Banghua Zhu, il est également l'un des cofondateurs de Nexusflow et a désormais officiellement rejoint NVIDIA en tant que directeur de recherche et scientifique distingué.
Jiao a un total de 7 259 citations et un indice h de 34. Ses articles représentatifs incluent « Compromis théoriquement fondé entre robustesse et précision » et « Bridging Offline Reinforcement Learning and Imitation Learning : A Tale of Pessimism » co-écrit avec Banghua Zhu et al., tous deux publiés dans des conférences de premier plan telles que NeurIPS.
Claude → Curseur
Catherine Wu
Catherine Wu a travaillé comme chef de produit pour Claude Code chez Anthropic, où elle se concentrait sur la création de systèmes d'IA fiables, explicables et contrôlables. Selon The Information, Catherine Wu a été recrutée par Cursor, une start-up de programmation en IA, pour occuper le poste de chef de produit.

Avant de rejoindre Anthropic, elle était associée au sein de la célèbre société de capital-risque Index Ventures, où elle a travaillé pendant près de trois ans, période durant laquelle elle a été profondément impliquée dans les investissements de démarrage et le soutien stratégique de nombreuses startups de premier plan.
Sa carrière n’a pas débuté dans le milieu de l’investissement, mais s’est enracinée dans des postes techniques de première ligne.
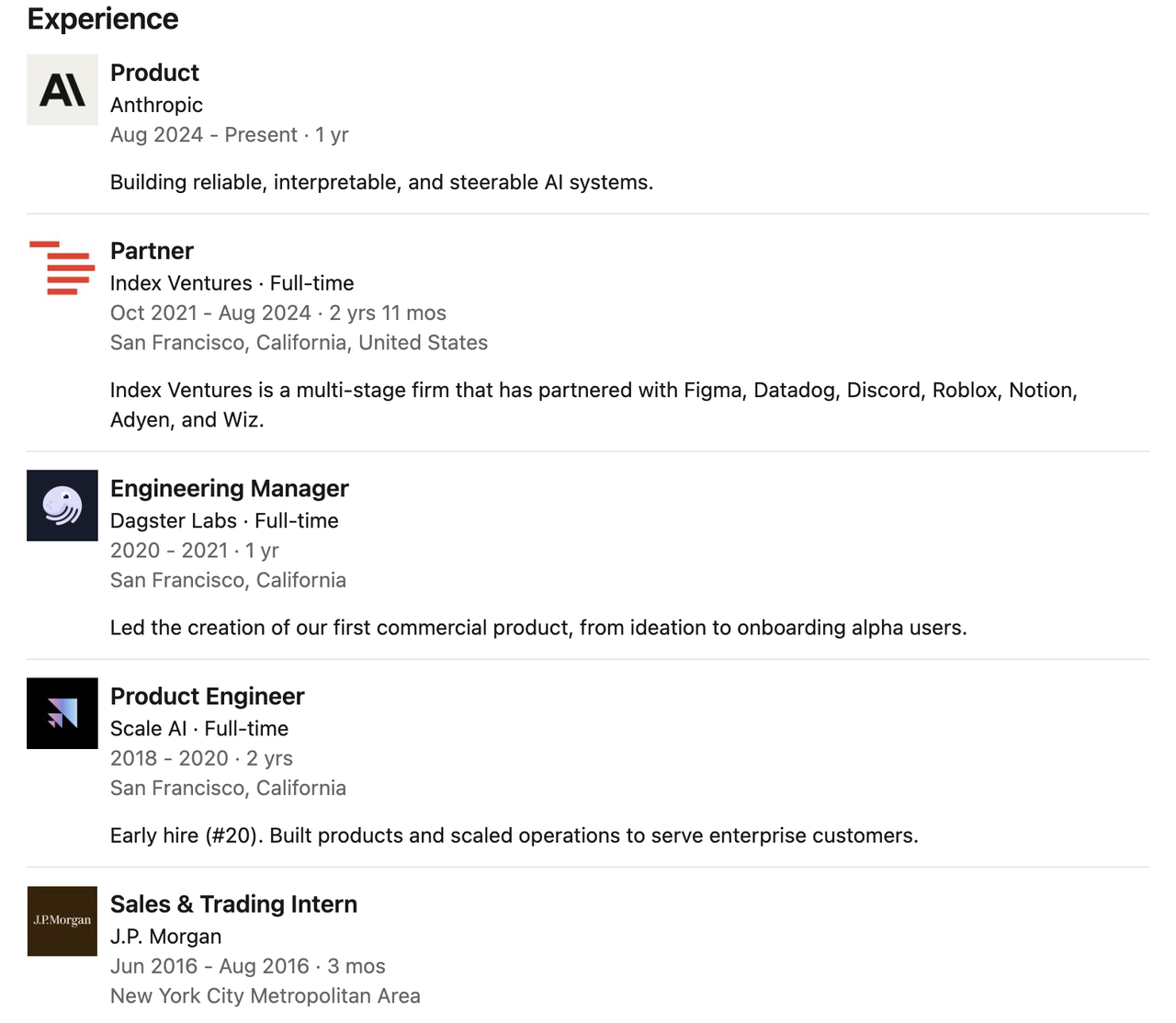
Elle a précédemment travaillé comme responsable de l'ingénierie chez Dagster Labs, dirigeant le développement du premier produit commercial de l'entreprise, et comme ingénieur produit précoce chez Scale AI, participant à la construction et à l'expansion opérationnelle de plusieurs produits clés.
Auparavant, elle a effectué un stage chez JPMorgan Chase et obtenu une licence en informatique à l'Université de Princeton. Parallèlement à ses études, elle a également effectué un échange universitaire à l'École polytechnique fédérale de Zurich.
Tesla | Phil Duan
Phil Duan est l'ingénieur logiciel en chef de Tesla AI. Il est actuellement responsable de l'équipe Fleet Learning d'Autopilot et s'engage à promouvoir la construction du module central « données + perception » du système de conduite autonome (FSD) de Tesla.

Il a dirigé l'équipe Tesla pour développer un moteur de données à haut débit et à itération rapide, capable de collecter, de traiter et d'annoter automatiquement les données de conduite de millions de véhicules, en mettant l'accent sur l'optimisation coordonnée de la qualité, de la quantité et de la diversité des données. Dans le domaine de la perception, il a dirigé la construction de plusieurs réseaux neuronaux clés, notamment des modèles visuels de base, la détection de cibles, la prédiction de comportement, les réseaux d'occupation, le contrôle du trafic et les systèmes d'aide au stationnement de haute précision. Il est également l'un des principaux concepteurs du système de perception Autopilot.
Il est titulaire d'une licence en sciences et technologies de l'information optique de l'Université de technologie de Wuhan, puis d'un doctorat et d'un master en génie électrique de l'Université de l'Ohio, spécialisé en avionique. Il a remporté le prix William E. Jackson 2019 de la RTCA pour sa thèse de doctorat, l'une des plus hautes distinctions décernées aux étudiants diplômés en avionique et télécommunications aux États-Unis.
#Bienvenue pour suivre le compte public officiel WeChat d'iFanr : iFanr (ID WeChat : ifanr), où du contenu plus passionnant vous sera présenté dès que possible.