
Le premier jeu multijoueur IA au monde est là ! Votre ancien ordinateur peut également jouer Ci-joint l’adresse de téléchargement

Jouer à des jeux avec l’IA n’a rien de nouveau ; Les jeux de programmation IA n’ont rien de nouveau non plus.
Mais utiliser l’IA pour créer un monde de jeu prenant en charge l’interaction en temps réel entre deux personnes, des perspectives cohérentes et une synchronisation logique ? Cela s'est produit pour la première fois aujourd'hui.
L'équipe israélienne Enigma Labs a annoncé aujourd'hui la sortie du premier jeu multijoueur au monde généré par l'IA – Multiverse sur la plateforme X. Le nom semble avoir été produit par Marvel, et le gameplay est en effet de la science-fiction.
La dérive et le crash sont tous synchronisés, les opérations se répondent et les détails peuvent correspondre à la fréquence d'images.
Tout dans le jeu n'est plus contrôlé par des scripts prédéfinis ou des moteurs physiques, mais est généré en temps réel par un modèle d'IA, garantissant que les deux joueurs voient le même monde logiquement unifié.

De plus, Multiverse est entièrement open source : le code, les modèles, les données et les documents sont tous disponibles sur GitHub et Hugging Face. Vous pouvez même l'exécuter directement sur votre ordinateur.
Clément Delangue, PDG de Hugging Face, a également lancé un appel en ligne sur la plateforme X :
C'est l'ensemble de données le plus cool que j'ai vu sur Hugging Face aujourd'hui : des étiquettes d'action pour les courses 1v1 dans Gran Turismo 4, utilisées pour entraîner un modèle mondial multijoueur.
Les véhicules changent constamment de position sur la piste, dépassant, dérivant, accélérant, puis rejoignant un certain tronçon.

Alors, à quoi sert ce modèle appelé Multiverse ? L'équipe technique officielle a partagé plus de détails de construction dans un blog technique.
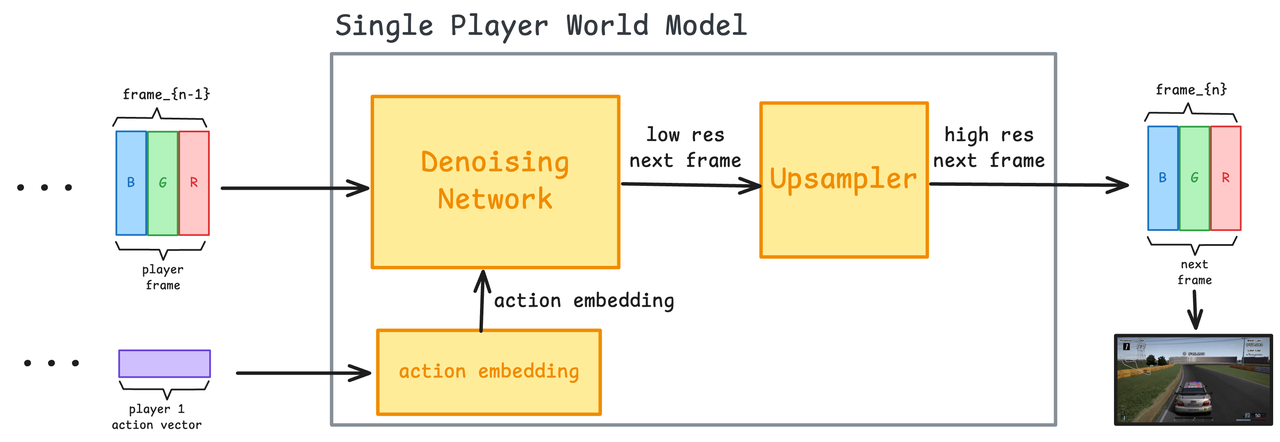
Avant cela, nous devons introduire le modèle mondial traditionnel de l’IA : vous l’exploitez et il prédit comment l’image doit être générée. Le modèle examine vos opérations, examine les images précédentes, puis génère l'image suivante. Le principe n'est pas difficile à comprendre :
- Intégration d'action : convertissez les opérations du joueur (telles que la touche sur laquelle vous avez appuyé) en vecteurs d'intégration
- Réseau de débruitage : utilisez un modèle de diffusion pour prédire la trame suivante en combinant les opérations et les trames précédentes.
- Suréchantillonneur (facultatif) : améliore la résolution et les détails des images générées
Mais une fois qu’un deuxième joueur est introduit, le problème se complique.
Le bug le plus typique est que la voiture de votre côté vient de heurter le garde-corps, mais que le côté adverse continue d'accélérer ; vous sortez de la piste, mais l'adversaire ne voit même pas où vous êtes. L’expérience de jeu entière est comme deux images bloquées et désynchronisées.
Multiverse est le premier modèle mondial d’IA capable de synchroniser les perspectives de deux joueurs. Peu importe ce qui arrive à l’un des joueurs, l’autre peut le voir sur son propre écran en temps réel, sans délai ni conflit logique.
C’est également quelque chose qui a été difficile à réaliser dans les simulations d’IA dans le passé : la cohérence multi-vues.
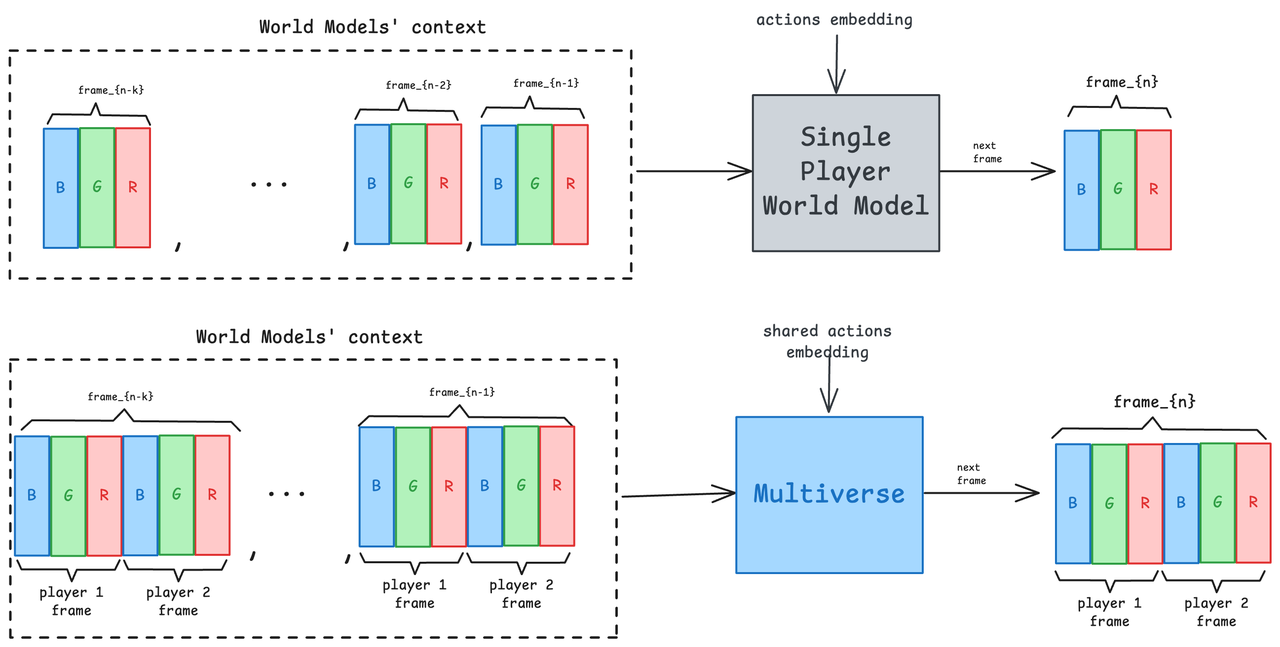
Pour résoudre ce problème et construire un modèle mondial multijoueur véritablement collaboratif, l’équipe Multiverse a trouvé une solution très intelligente. Ils ont conservé les composants de base et en même temps complètement brisé et reconstruit l'idée originale de « prédiction par une seule personne » :
- Action embedder : reçoit les actions de deux joueurs et génère un vecteur d'intégration qui intègre les opérations des deux parties ;
- Réseau de débruitage : Réseau de diffusion, qui génère des images de deux acteurs en même temps pour garantir leur cohérence dans l'ensemble ;
- Upsampler : similaire au mode solo, mais traite et améliore les images des deux joueurs simultanément.
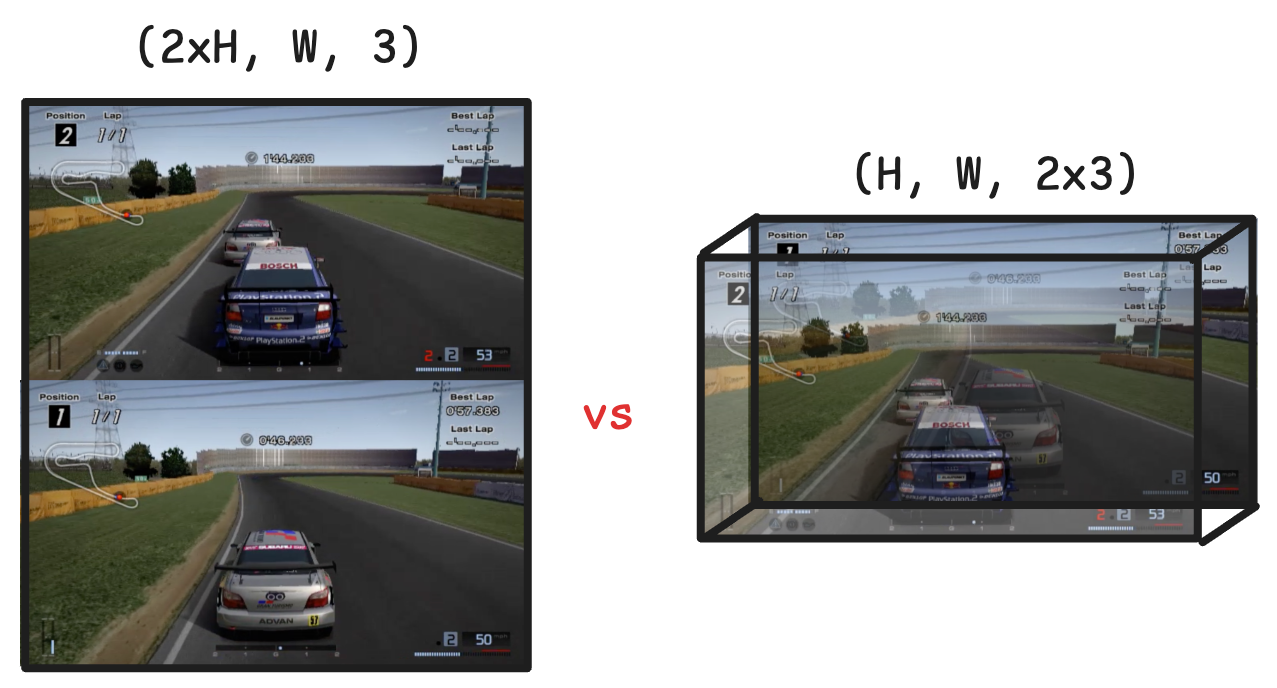
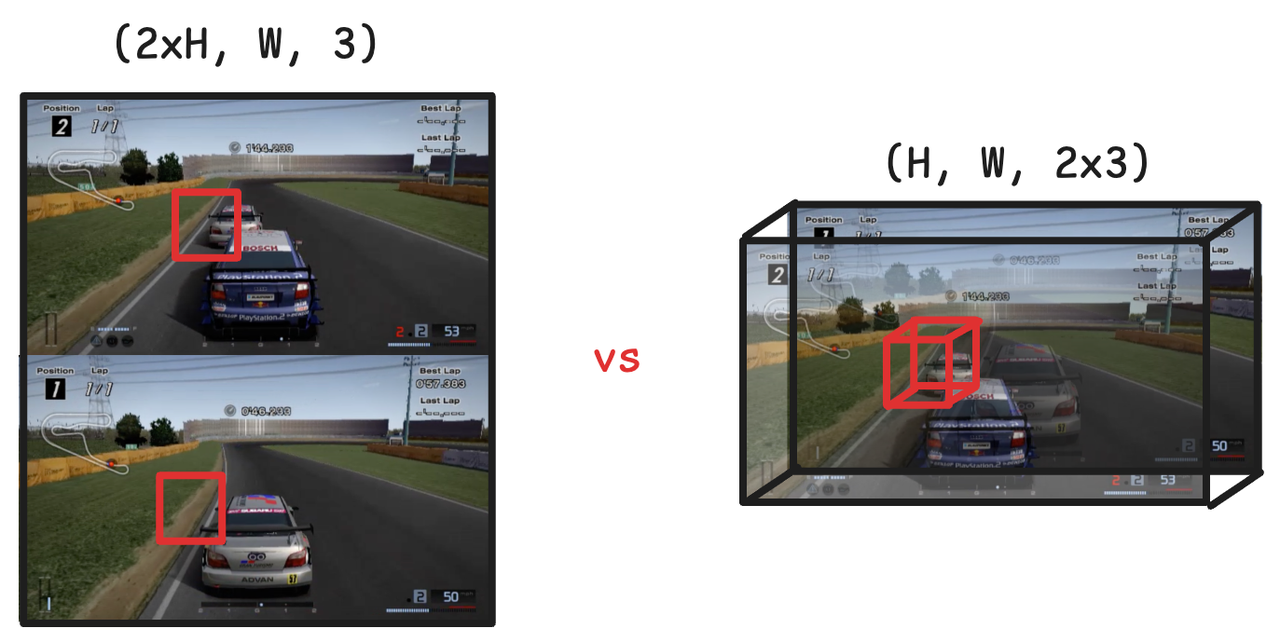
À l'origine, lorsqu'il s'agissait d'une image de deux personnes, la première réaction de beaucoup de gens était de diviser l'écran : séparer les deux images et les générer séparément.
Cette idée est simple et grossière, mais elle est difficile à synchroniser, consomme des ressources et a des effets médiocres. Cependant, ils ont pensé à « assembler » les perspectives des deux joueurs en une seule image, en fusionnant leurs contributions dans un vecteur d'action unifié et en traitant l'ensemble comme une « scène unifiée ».
La méthode spécifique est l'empilement de l'axe des canaux : traiter les deux images comme une seule image avec le double des canaux de couleur.
Cette chose semble petite, mais elle est en réalité très intelligente sur le plan technique. Étant donné que le modèle de diffusion utilise l'architecture U-Net, le noyau est la convolution et la déconvolution, et le réseau neuronal convolutif a une forte conscience structurelle de la dimension du canal.
En d’autres termes, il ne s’agit pas de coller deux mondes ensemble, mais de permettre au modèle de savoir à partir de la « couche inférieure des neurones » que les deux images sont liées et doivent être générées de manière collaborative. L'image finale n'a pas besoin d'être alignée manuellement, elle est naturellement synchronisée.
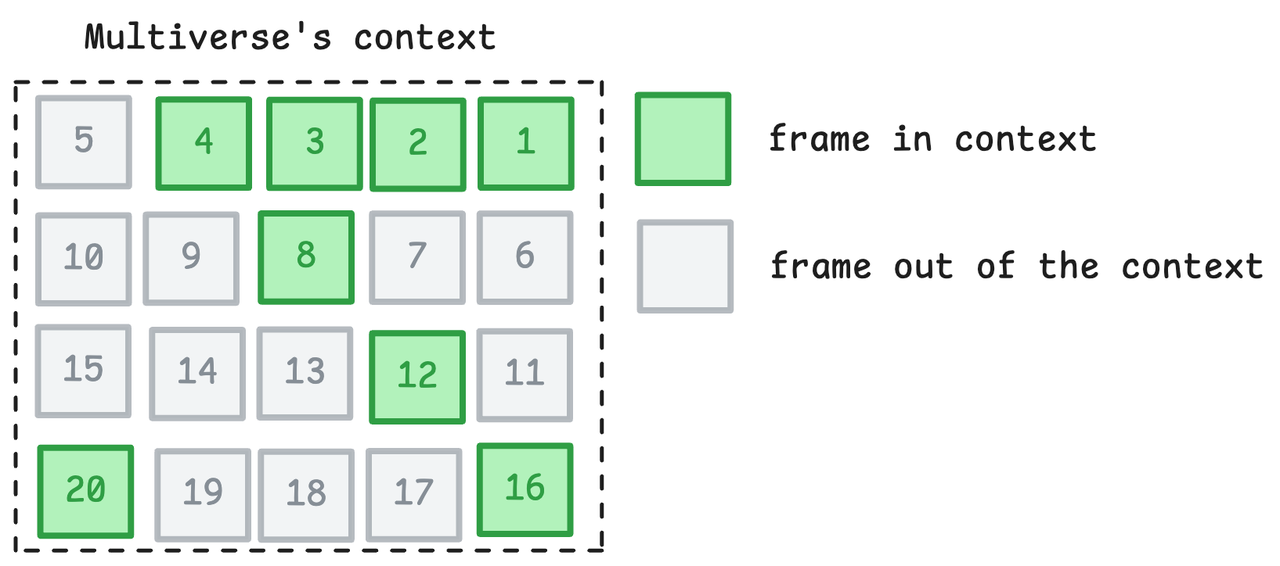
Mais pour que le modèle puisse prédire avec précision l'image suivante, une chose doit être comprise : la vitesse et la position relative du véhicule sont dynamiques, et suffisamment d'informations doivent être disponibles pour une prédiction précise. Ils ont constaté que 8 images (à 30 ips) suffisent pour apprendre des fonctionnalités cinématiques telles que l’accélération, le freinage et la direction.
Mais le problème est le suivant : la vitesse relative telle que le dépassement est beaucoup plus lente que la vitesse absolue (environ 100 km/h contre 5 km/h). Si le numéro de cadre est trop proche, le modèle ne peut pas du tout percevoir le changement.
Ils ont donc conçu une solution de compromis : l'échantillonnage clairsemé :
- Fournit les 4 dernières images consécutives (garantissant une réponse immédiate) ;
- Fournit 4 images supplémentaires d'images historiques « échantillonnées toutes les 4 images » ;
- L'image la plus ancienne est à 20 images de l'image actuelle, soit il y a environ 0,666 seconde.
Pour permettre au modèle de réellement comprendre la « conduite coopérative », il ne peut pas s'appuyer uniquement sur ces données d'entrée, mais nécessite également une formation intensive sur les comportements interactifs.
Les tâches traditionnelles en solo (telles que marcher, tirer) ne nécessitent une prédiction que sur une courte fenêtre de temps, par exemple 0,25 seconde. Cependant, sous l'interaction de plusieurs personnes, un si petit changement de temps est minime et ne reflète pas du tout le « sens du travail d'équipe ».
La solution de Multiverse consiste simplement à laisser le modèle prédire une séquence comportementale pouvant aller jusqu'à 15 secondes pour capturer la logique d'interaction à long terme et à plusieurs tours.
La méthode de formation ne se limite pas à 15 secondes à la fois, mais utilise une stratégie « d'apprentissage du programme » : en commençant à partir de 0,25 seconde de prédiction et en l'étendant progressivement jusqu'à 15 secondes. De cette façon, le modèle apprend d'abord des fonctionnalités de bas niveau telles que la structure de la voiture et la géométrie de la piste, puis maîtrise lentement des concepts de haut niveau tels que les stratégies des joueurs et la dynamique du jeu.
Après formation, les performances du modèle en termes de persistance des objets et de cohérence inter-frame ont été considérablement améliorées. Bref, la voiture ne disparaîtra pas d’un coup, et la logique ne s’effondrera pas non plus.
Ces excellentes performances de formation sont attribuées à l’ensemble de données soigneusement sélectionnées. C'est vrai, il s'agit du chef-d'œuvre de simulation de course PS2 de 2004 : Gran Turismo 4.
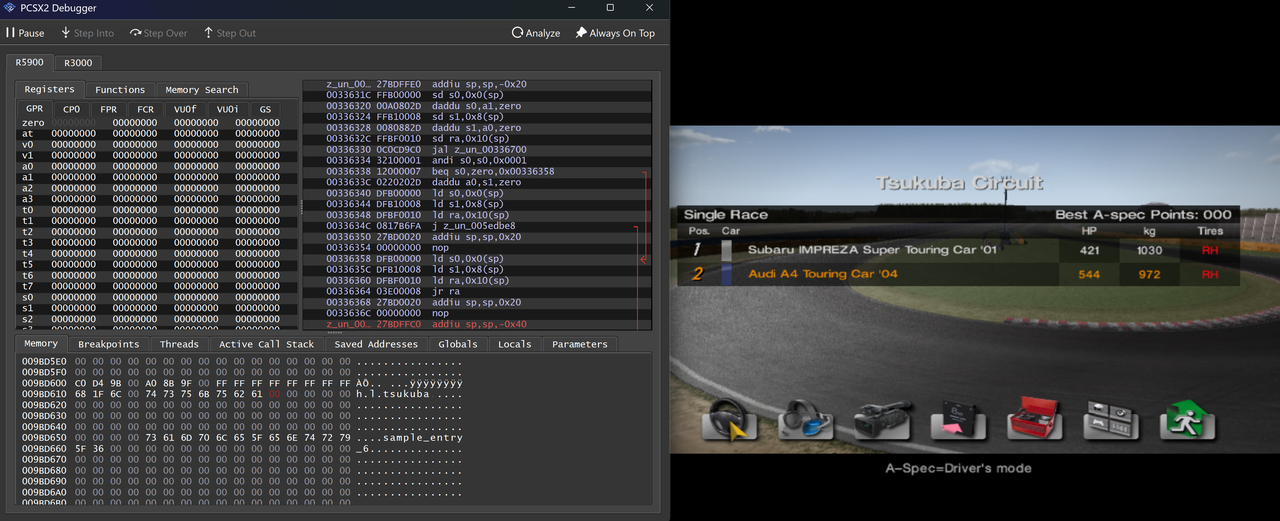
Bien sûr, afin d'éviter toute responsabilité, l'équipe Multiverse n'a pas oublié de plaisanter en disant qu'elle est un fan inconditionnel de Sony.
Leur scène de test était une course en 1 contre 1 sur le circuit de Tsukuba, mais le problème est que GT4 ne prend pas nativement en charge la « relecture en perspective 1v1 ». Ils l’ont donc procédé à une ingénierie inverse et ont transformé le jeu en un véritable mode 1v1.
alors:
- Enregistrez chaque partie deux fois, une fois pour vous voir et une fois pour voir votre adversaire ;
- Ensuite, grâce au traitement de synchronisation, il est fusionné en une vidéo complète, montrant la bataille en temps réel entre les deux camps.
Qu’en est-il des données clés ? Après tout, le jeu lui-même ne fournit pas de journaux d’opérations.
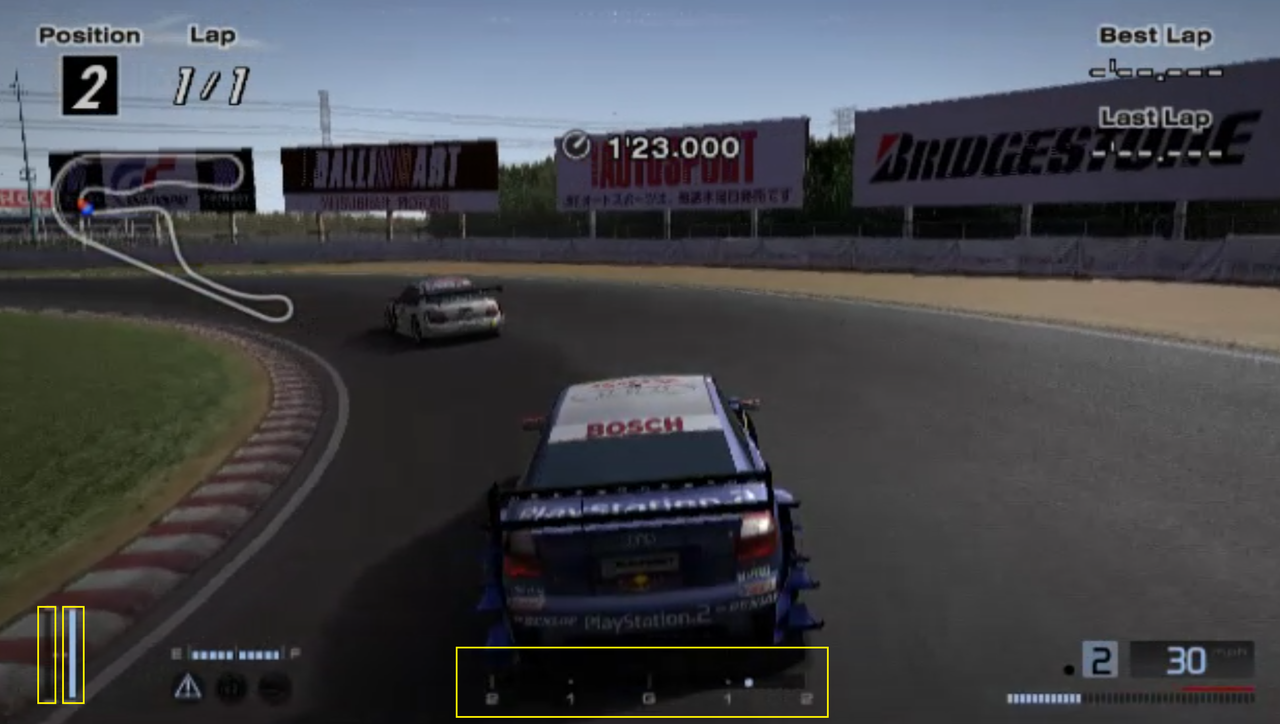
La réponse est qu'ils utilisent les informations affichées par le HUD du jeu (barres indicatrices d'accélérateur, de frein et de volant), utilisent la vision par ordinateur pour extraire les barres d'accélérateur, de frein et de direction affichées sur l'écran de jeu image par image, puis en dérivent les instructions de contrôle.
En d’autres termes, l’opération peut être restaurée uniquement en s’appuyant sur les informations de l’écran, sans avoir besoin de fichiers journaux supplémentaires.
Bien entendu, ce processus est inefficace et il est impossible d’enregistrer manuellement chaque match deux fois.
Ils ont découvert que GT4 possède une fonctionnalité cachée appelée mode B-Spec, qui permet à l'IA de conduire seule. J'ai donc écrit un script pour envoyer des instructions aléatoires à l'IA, lui permettant de s'emballer et de planter toute seule, générant ainsi des ensembles de données par lots.
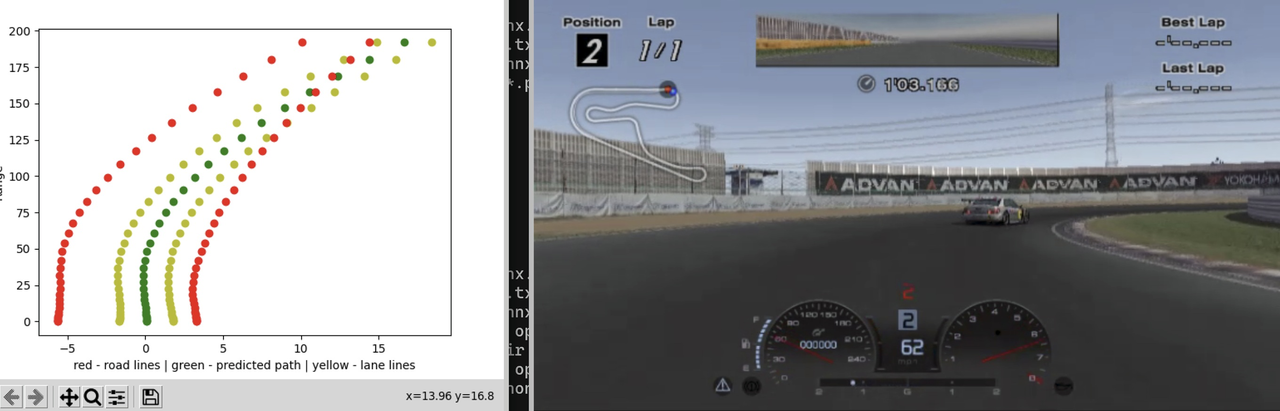
À propos, ils ont également essayé d'utiliser le modèle de conduite autonome d'OpenPilot pour contrôler les personnages du jeu. Bien que l'effet ait été bon, en termes d'efficacité et de stabilité, B-Spec est plus adapté à la formation à grande échelle.
Voici le point clé : parler des effets sans parler des coûts est naturellement un hooliganisme.
Un tel modèle d'IA capable d'exécuter des mondes multi-vues, de synchroniser des images et de stabiliser la sortie, y compris le modèle, la formation, les données et l'inférence, ne coûte que 1 500 $, ce qui équivaut à peu près à l'achat d'une carte graphique haut de gamme.

Jonathan Jacobi, employé de Multiverse, a publié sur X :
Nous avons construit Multiverse avec seulement 1 500 $. La clé n’est pas la puissance de calcul, mais l’innovation technologique.
Plus important encore, Jacobi estime que le modèle mondial multijoueur n’est pas seulement une nouvelle façon pour l’IA de jouer à des jeux, mais aussi la prochaine étape dans la technologie de simulation. Il ouvre la voie à un tout nouveau monde : un environnement dynamique co-évolué et co-façonné par les joueurs, les agents et les robots.
À l'avenir, le modèle du monde pourrait ressembler à une version virtuelle de la société réelle : vous et l'IA y coexisterez, formant un « univers dynamique » très réaliste qui possède également une logique d'interaction complexe proche de la société réelle.
Alors, cela vous semble-t-il un peu joyeux ?
Ci-joint l'adresse de référence :
GitHub : https://github.com/EnigmaLabsAI/multiverse
Ensemble de données Hugging Face : https://huggingface.co/datasets/Enigma-AI/multiplayer-racing-low-res
Modèle Hugging Face : https://huggingface.co/Enigma-AI/multiverse
Blog officiel : https://enigma-labs.io/blog
# Bienvenue pour suivre le compte public officiel WeChat d'aifaner : aifaner (WeChat ID : ifanr). Un contenu plus passionnant vous sera fourni dès que possible.
Ai Faner | Lien original · Voir les commentaires · Sina Weibo